The Intel Xeon E7 v2 Review: Quad Socket, Up to 60 Cores/120 Threads
by Johan De Gelas on February 21, 2014 6:00 AM EST- Posted in
- IT Computing
- Intel
- Xeon
- Ivy Bridge EX
- server
- Brickland
Power consumption
By the virtue of the impressive 22nm Hi-K metal-gate tri-gate 22nm CMOS with 9 metal layers, Intel has been able to increase the maximum core count by 50% (15 vs 10) and the clockspeed by 17% (2.8GHz vs 2.4GHz) while the TDP has only increased by 19% (155W vs 130W). Intel claims that the actual power usage of the new flagship E7, the 155W 4890 v2, is actually lower than the previous 130W TDP Xeon E7-4870 at low and medium loads.
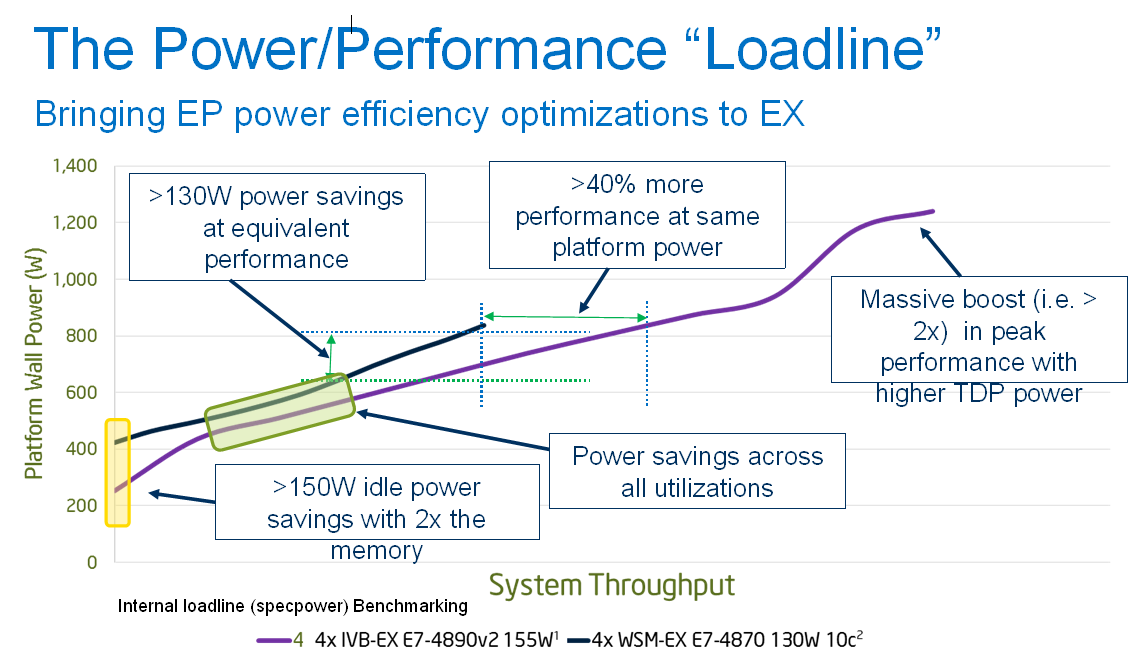
At maximum load, Intel claims you get about 50% higher power consumption for twice as much performance. At idle and low loads, it seems that the 155W Xeon 4890 v2 is a lot more efficient. That makes sense considering the improvements in idle/low load power use we saw with Sandy Bridge and then Ivy Bridge over the earlier Nehalem/Clarksfield offerings on desktops and laptops; it's taken some time, but the big servers are finally seeing the same improvements with Ivy Bridge EX.








125 Comments
View All Comments
DanNeely - Friday, February 21, 2014 - link
" In a nutshell, every effort is made to ensure you cannot compare these with the servers of "Big Blue" or the x86 competition."Of course not. If they did that it would interfere with their deceptive marketing campaign with the banner headline "An Oracle Box costing $$stupid is several times faster than an IBM box costing $$3xStupid"; where if you look up model dates you see they're comparing against a several year old IBM box against their latest and greatest. (I've never been bored enough to dig that deeply; but my inner cynic suspects that they're probably larding a bunch of expensive stuff that doesn't do anything for java onto the IBM box to inflate its price even more.)
Brutalizer - Sunday, February 23, 2014 - link
The reason Oracle sometimes compares to an older IBM model, is because IBM has not released newer benchmarks. IBM does the same, for instance, IBM claims that, one z10 Mainframe with 64 sockets can replace 1.500 of the x86 servers. If you dig a bit, it turns out all x86 servers are like 1GHz Pentium3 with 256MB RAM or so - and they all idle. Yes, literally, all x86 servers idle, whereas the Mainframe is 100% loaded. What happens if some x86 servers starts to do some work? The Mainframe will choke. I can emulate a Mainframe on my laptop with open source emulator "TurboHercules", is it ok if I claim that my laptop can replace three IBM Mainframes (if they all idle)?Regarding this Intel Xeon E7 cpu. Sure it is nice, but it has twice the number of cores as the competition. Another thing is that the largest x86 servers have 8-sockets. There are no larger x86 servers than that. The only 32 socket servers are Unix and Mainframes. Some Unix servers even have 64 sockets. Thus, the x86 does not scale above 8-sockets.
For scalability, you must distinguish between scale-out and scale-up. Scale-out is a cluster, just add a new node and you have increased scalability. Clusters are used for HPC number crunching workloads where you run a tight for loop on some independent data (ideally each node fits everything in the cpu cache). Some examples of Scale-out servers (clusters) are all servers on the Top-500 supercomputer list. Other examples are SGI Altix / UV2000 servers or the ScaleMP server, they have 10,000s of cores and 64 TB RAM or more, i.e. cluster. Sure, they run a single unified Linux kernel image - but they are still clusters. If you read a bit, you will see that the SGI servers are using MPI. And MPI are used on clusters for HPC number crunching.
Scale-up servers, are one single fat huge server. They might have 16 or 32 sockets, some even have 64 sockets! They weigh 1000 kg and costs many many millions. For instance the old IBM P595 Unix server for the old TPC-C record, has 32 sockets and costs $35 million (no typo). One single server with 32 cpus, costs $35 million. You will never ever see this prices on clusters. If you buy a SGI server with 100s of sockets, you will essentially pay the same price as buying individual nodes with the same nr of sockets. But scale-up servers, need heavy redesign and innovative scalability tech, and that is the reason a 16 or 32 socket server costs many many many more times than a SGI cluster having 100s of sockets. They are not in the same arena. These scale-up servers are typically used for SMP workloads, not HPC workloads. SMP workloads are typically large databases or Enterprise ERP workloads. This code is heavy branch intensive, so you can not fit into a cpu cache. It branches everywhere, and clusters can not run these Enterprise workloads because the performance would be very bad. If you need to run Enterprise workloads (where the big margin and big money is) you need to go to 32 socket servers. And they are all RISC or Mainframe servers. Examples are IBM P795, Oracle M6-32, Fujitisu M10-4S, HP Superdome/Integrity. They all run AIX, Solaris, HP-UX and they all have up to 32 sockets or 64 sockets. Some attempts have been made to compile Linux to these huge servers, but the results have been bad because Linux has problems scale above 8-sockets. The reason is the Linux kernel devs does not have access to 32 socket SMP server, because they dont exist, so how can Linux kernel be optimized for 32 sockets? Ted Tso, the famous Linux kernel developer writes:
http://thunk.org/tytso/blog/2010/11/01/i-have-the-...
"...Ext4 was always designed for the “common case Linux workloads/hardware”, and for a long time, 48 cores and large RAID arrays were in the category of “exotic, expensive hardware”, and indeed, for much of the ext2/3 development time, most of the ext2/3 developers didn’t even have access to such hardware...."
Ted Tso considers servers with 48 cores in total, to be huge and out of reach for Linux developers. He is not talking about 48 socket servers, but 48 cores which is chicken shit in the mature Enterprise arena.
For instance the Big Tux HP server, compiled Linux to 64 socket HP integrity server with catastrophic results, the cpu utilization was ~40%, which means every other cpu idles under full load. Google on Big Tux and read it yourself.
There is a reason the huge Linux servers such as SGI UV2000 with 1000s of cores are so cheap in comparison to 16 socket or 32 socket Unix servers, and why the Linux servers are exclusively used for HPC number crunching workloads, and never SMP workloads:
SGI servers are only used for HPC clustered workloads, and never for SMP enterprise workloads:
http://www.realworldtech.com/sgi-interview/6/
"Typically, much of the work in HPC scientific code is done inside loops, whereas commercial applications, such as database or ERP software are far more branch intensive. This makes the memory hierarchy more important, particularly the latency to main memory. Whether Linux can scale well with a workload is an open question. However, there is no doubt that with each passing month, the scalability in such environments will improve. Unfortunately, SGI has no plans to move into this SMP market, at this point in time."
Same with the ScaleMP Linux server with 1000s of cores, is never used for SMP workloads:
http://www.theregister.co.uk/2011/09/20/scalemp_su...
"The vSMP hypervisor that glues systems together is not for every workload, but on workloads where there is a lot of message passing between server nodes – financial modeling, supercomputing, data analytics, and similar parallel workloads. Shai Fultheim, the company's founder and chief executive officer, says ScaleMP has over 300 customers now. "We focused on HPC as the low-hanging fruit."
The difficult thing is to scale well above 8 sockets. You can release one single strong cpu, which does not scale. To scale above 8-sockets are very difficult, ask Intel. Thus, this Intel Xeon E7 cpu are only used up to 8-sockets servers. For more oomph, you need 32 socket or even 64 sockets - Unix or Mainframes. SGI Linux servers can not replace these large Unix servers. And that is the reason Linux never will venture into the lucrative Enterprise arena, and never replace large Unix servers. The largest Linux servers capable of Enterprise SMP workloads are 8 sockets. The Linux clusters dont count.
Another reason why this Intel Xeon E7 can not touch the high end server market (beyond scalability limitations) is that the RAS is not good enough. RAS is very very expensive. For isntance, IBM Mainframes and high end SPARC cpus, can replay an instruction if it were an error. x86 can not do this. Some Mainframes have three cpus and compare every computation, and if there is an error, the failing cpu will shut down. This is very very expensive to create this tailor made hardware. It is easy to get good performance, just turn up the GHz up to unstability point. But can you rely on that hardware? No. Enterprise need reliability above else. You must trust your hardware. It is much better to have one slower reliable server, than a super fast cranked up GHz where some computations are false. No downtime! x86 can not do this. The RAS is lacking severly behind and will take decades before Intel can catch up on Unix or Mainframe servers. And at that point - the x86 cpus will be as expensive!
Thus:
-Intel Xeon E7 does not scale above 8-sockets. Unix does. So you will never challenge the high end market where you need extreme performance. Besides, the largest Unix servers (Oracle) have 32TB RAM. Intel Xeon E7 has only 6TB RAM - which is nothing. So x86 does not scale cpu wise, nor RAM wise.
-Intel Xeon E7 has no sufficient RAS, and the servers are unreliable, besides the x86 architecture which is inherently buggy and bad (some sysadmins would not touch a x86 server with a ten feet pole, and only use OpenVMS/Unix or Mainframe):
http://www.anandtech.com/show/3593
-Oracle is much much much much cheaper than IBM POWER systems. The Oracle SPARC servers pricing is X for each cpu. So if you buy the largest M6-32 server with 32TB of RAM you pay 32 times X. Whereas IBM POWER systems costs more and more the more sockets you buy. If you buy 32 sockets, you pay much much much more than for 8 sockets.
Oracle will release a 96-socket SPARC server with up to 96TB RAM. It will be targeted for database work (not surprisingly as Oracle is mainly interested in Databases) and other SMP workloads. Intel x86 will never be able to replace such a huge monster. (Sure, there are clustered databases running on HPC servers, but they can not replace SMP databases). Look at the bottom pic, to see how all sockets are connected to each other in 32 socket configuration. There are only 2-3 hops to reach each node, which is very good. For HPC clusters, the worst case requires many many hops, which makes them unusable for SMP workloads
http://www.theregister.co.uk/2013/08/28/oracle_spa...
TerdFerguson - Sunday, February 23, 2014 - link
Great post, Brutal. Where can I read more of your writing?JohanAnandtech - Sunday, February 23, 2014 - link
32 sockets to run SMP workloads. " typically large databases or Enterprise ERP workloads". Sound like we are solving a problem with hardware instead of being innovative in software."Intel Xeon E7 has only 6TB RAM - which is nothing".
Dangerous comment. 12 TB is possible with an octal Xeon at a fraction of the cost of the unix boxes you talk about. 1 - 12 TB is enough for a massive part of the market, even a large part of the "lucrative" enterprise market.
I agree with you that there are some workloads which are out of the Xeon's league. But it is shrinking...each time a bit more.
"than a super fast cranked up GHz where some computations are false"
That is another bad statement without any proof.
"The RAS is lacking severly behind and will take decades before Intel can catch up on Unix or Mainframe servers. And at that point - the x86 cpus will be as expensive!"
Considering that the vast majority of problems is related to software (drivers inclusive), I doubt very much that even better RAS can make a big difference. A mature software stack is what make these monster servers reliable, the hardware plays a small role.
Secondly, Intel charges just as much as the market is willing to pay. They can spread the core development over much more CPUs than the RISC vendors, so chances are that they will never as expensive as the RISC vendors.
FunBunny2 - Sunday, February 23, 2014 - link
-- Sound like we are solving a problem with hardware instead of being innovative in softwareWell, it depends on what one means by "innovation". The Kiddie Koders have been recreating the likes of IDMS & IMS (early to mid 1960s approaches), all with newer names by identical semantics and storage models. The way to leverage such machines, relational data is the answer. Minimum storage footprint, DRI, and such. Use SSD, and beat the crap out of these neer-do-well RBAR messes.
xakor - Sunday, February 23, 2014 - link
"Innovative software stacks" might imply something modern and better like immutable databases which are at the opposite end of the spectrum vs IMS placing relational databases inbetween. Read up http://engineering.linkedin.com/distributed-system... concrete examples of good paradigms would be Datomic as well as Event Store.xakor - Sunday, February 23, 2014 - link
Don't get me wrong those database benefit from huge servers with loads of RAM just the same.Brutalizer - Sunday, February 23, 2014 - link
6TB or 12TB is not really interesting as we are entering the Large Data age. Oracle has 32TB today, and with compression you can run huge databases from RAM. And the 96-socket server will have 96TB RAM, which will run databases even faster. Databases are everything, they are at the heart of a company, without databases the company will halt. There are examples of companies not having a backup of their database going bankrupt when their database got wiped out because of a crash. The most important part of a company, is the database, the infromation.I am trying to say that it is better to have a slow and 100% reliable server, than a fast overclocked server that is a bit unstable - for Enterprise customers. There are things that must not go down, no crashes allowed.
For large workloads, Oracle SPARC is the widening the gap to all other cpus, because Oracle is doubling performance every generation. Intel does not do that, nor does IBM. Try to benchmark a 8-socket x86 server against the Oracle 32-socket SPARC M5-32 monster server. Or against the Fujitsu 64 socket M10-4S server sporting the Fujitsu developed SPARC Venus cpu:
http://www.theregister.co.uk/2012/10/01/fujitsu_or...
Or the coming 96-socket SPARC server. :)
stepz - Wednesday, February 26, 2014 - link
A 32TB or 96TB server is also not really interesting for companies dealing with "Big Data" and big databases. What happens when your working set grows even more? Shut your company down and wait until Oracle manages to build an even larger database? These monsters are mainly interesting to companies where lack of software development foresight and/or capability had engineered them into a corner where they have to buy themselves out by getting a larger hammer. Smarter organizations pour their R&D into making their software and databases scale out and provide RAS on the cluster level. The monsters, while very sexy, are interesting for a tiny fraction of huge dinosaur corporations, and even those will slowly die out by succumbing to their own weight. The dying out will of course take a long time due to the amount of fat these corporations have managed to accumulate, providing ample lucrative options for companies facilitating their death by providing stupidly expensive solutions to problems better solved by changing how the game is played.Kevin G - Monday, February 24, 2014 - link
Intel's advantage in CPU design stems from massive consumer usage. The individual Ivy Bridge core used in these 15 core monster is the same fundamental design that was introduced to notebooks/desktops in 2012. Essentially the end consumers get to be the guinea pigs and any errata found within the first six months can be adopted into the server design before it ships. What makes these a server CPU is the focus on IO and RAS features outside of the CPU core (which have their own inherent design costs).IBM and the other RISC vendors don't have the luxury of a high volume design. Mainframe installations number between 10,000 and 20,000 depending on source. Not very many at either end of that spectrum. IBM's POWER installations are several times larger in terms of units but still dwarfed by just the x86 server unit shipments. On the high end, this has lead to some rather large prices from IBM:
http://www-01.ibm.com/common/ssi/ShowDoc.wss?docUR...
The one thing that matters for RAS is just uptime. The easiest way to get there is to cluster basic services so that a single node can be taken offline and addressed while the external interface fails over to another node. This basic principle is true regardless of hardware as you want to run a system in a minimum of a pair, ideally a primary pair with an offsite backup system. The one nice thing is that software licensing here isn't as dreadful as scaling up: often there is a small discount to make it less painful. Virtualization of smaller systems have helped in terms of RAS as being able to migrate running systems around a VM farm. Hypervisors are now supporting shadow images so that there is no additional network traffic for a VM to fail over to another node in case of a hardware failure. The x86 platform in many cases is 'good enough' that 99.999% uptime can be achieved with forward thinking resource planning.