Intel Clovertown: Quad Core for the Masses
by Jason Clark & Ross Whitehead on March 30, 2007 12:15 AM EST- Posted in
- IT Computing
Architecture & Roadmap
It's no secret that Clovertown isn't what the purists would call a "true quad core" architecture; it is two Woodcrest processors joined together in a single package. Does it matter? In our opinion, no. Clovertown performs very well, as you will see later in the article.
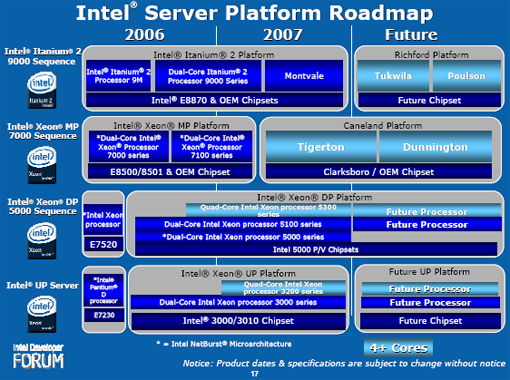
Clovertown is going to be with us for most of 2007 until Penryn is released, which is essentially a die shrink to 45nm. It is doubtful we will see a "true" quad core Intel part until the next generation architecture is released in 2008, code-named Nehalem. Below is the most recent server roadmap we have for the server platform. The part marked "Future Processor" in the Xeon DP Platform and UP Platform is Nehalem. You can read more about Nehalem and Penryn in our recent article on that subject.
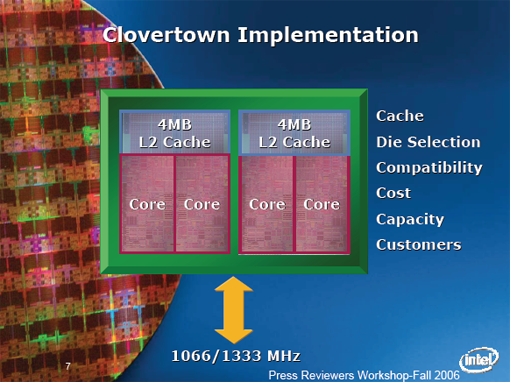
Clovertown at its heart is two Woodcrest parts connected together on a single package. Each pair of cores shares a single 4MB of L2 Cache, just like Woodcrest and the pair of cores shares a single 1066/1333 MHz pipe. For most Woodcrest systems, Clovertown will be a drop-in replacement after a BIOS upgrade. We tested the Clovertown in a spare Supermicro board we had in the lab, and had no issues upgrading it from dual core to quad core. For a more in-depth analysis of Clovertown architecture, check out a Johan's very thorough write-up on Clovertown.
It's no secret that Clovertown isn't what the purists would call a "true quad core" architecture; it is two Woodcrest processors joined together in a single package. Does it matter? In our opinion, no. Clovertown performs very well, as you will see later in the article.
Clovertown is going to be with us for most of 2007 until Penryn is released, which is essentially a die shrink to 45nm. It is doubtful we will see a "true" quad core Intel part until the next generation architecture is released in 2008, code-named Nehalem. Below is the most recent server roadmap we have for the server platform. The part marked "Future Processor" in the Xeon DP Platform and UP Platform is Nehalem. You can read more about Nehalem and Penryn in our recent article on that subject.
Clovertown at its heart is two Woodcrest parts connected together on a single package. Each pair of cores shares a single 4MB of L2 Cache, just like Woodcrest and the pair of cores shares a single 1066/1333 MHz pipe. For most Woodcrest systems, Clovertown will be a drop-in replacement after a BIOS upgrade. We tested the Clovertown in a spare Supermicro board we had in the lab, and had no issues upgrading it from dual core to quad core. For a more in-depth analysis of Clovertown architecture, check out a Johan's very thorough write-up on Clovertown.








56 Comments
View All Comments
timelag - Wednesday, April 4, 2007 - link
Authors--Er, gosh. Dunno what to make of the preceding discussion. Eh, they don't scare me--I'll post anyway.
Even though the title of this article is "Quad core for the masses", the benchmark is for enterprise database applications. Because of the title, I had expected some workstation benchmarking. Any plans for doing benchmarks for scientific and visualization applications? From bio-tech (BLAST, etc.), to fluid dynamics, to 3D rendering. That sort of thing.
Viditor - Wednesday, April 4, 2007 - link
Didn't mean to put you off there timelag...:)My apologies...
Some of what you're asking for was done in a http://www.anandtech.com/showdoc.aspx?i=2897&p...">previous article by Johan
Beenthere - Saturday, March 31, 2007 - link
Intel's attempt to use two dual cores on a slice of silicon and call it a quad core shows how easily they can manipulate the media with foolishness. Only a fool would buy Intel's inferior 2+2 design when they can have Barcelona and it's many superior derivatives.JarredWalton - Saturday, March 31, 2007 - link
Riiight... only a fool would get QX6700 right now when Barcelona isn't out. Two chips in a package has disadvantages, but there are certainly instances where it will easily outperform the 2x2 Opteron, even in eight-way configurations. There are applications that are not entirely I/O bound, or bandwidth bound. When it comes down to the CPU cores, Core 2 is significantly faster than any Opteron right now.As an example, a 2.66 GHz Clovertown (let alone a 3.0 GHz Xeon) as part of a 3D rendering farm is going to be a lot better than two 2.8 GHz (or 3.0 GHz...) Opteron parts. Two Xeon 5355 will also be better than four Opteron 8220 in that specific instance, I'm quite sure. The reason is the 4MB per chip L2 is generally enough for 3D rendering. There are certainly other applications where this is the case, but whether they occur more than the other way (i.e. 4x2 Opteron being faster than 2x4 Xeon) I couldn't say.
AMD isn't really going to have a huge advantage because of native quad core with Barcelona, and Intel wouldn't get a huge boost by having native quad core either. If you thought about it more, you would realize that the real reason Intel's quad core chips have issues with some applications is that all four cores are pulling data over a single FSB connection - one connection per socket. Intel has to use that single FSB link for RAM, Northbridge, and inter-CPU communications.
In contrast AMD's "native quad core" will have to have all four cores go over the same link for RAM access (potential bottleneck). They can use another HT link to talk to another socket (actually two links), and they can use the third HT link to talk to the Northbridge. The inter-CPU communication generally isn't a big deal, and Northbridge I/O is also a much smaller piece of the bandwidth pie than RAM accesses. It's just that AMD gets all the RAM bandwidth possible. AMD could have done a "two die in one package" design and likely had better scaling than Intel, but they chose not to.
And of course Intel will be going to something similar to HyperTransport with Nehalem in 2008. Even they recognize that the single FSB solution is getting to be severely inadequate for many applications.
Viditor - Saturday, March 31, 2007 - link
Actually, that's not true Jarred.
http://www.anandtech.com/showdoc.aspx?i=2897&p...">Johan's test benchmarked exactly that scenario, and C2D was equal at 4 cores and slightly slower at 8 cores. This was a 2.33 GHz Clovertown vs the 2.4 GHz Opterons...
Viditor - Saturday, March 31, 2007 - link
Let me add that there are cases where it could be true, but only when the apps don't scale at all...and in that case, even a single or dual core sometimes beats the Clovertowns.JarredWalton - Sunday, April 1, 2007 - link
Okay, wrong example then. Heh. The point is I am sure there are benchmarks where the FSB bottleneck isn't as pronounced. Anything that can stay mostly within the CPU cache will be very happy with the current Xeon 53xx chips. Obviously, the decision as to what is important will be the deciding factor, so companies should research their application needs first and foremost.Getting back to the main point of the whole article, clearly there are areas where Opteron can outperform Xeon with an equal number of cores. Frankly, I doubt 1600 FSB is going to really help, hence the need for the new high speed link with Nehalem on the part of Intel. K10 could very well end out substantially ahead in dual and quad socket configurations later this year, even if it only runs at 2.3 GHz. I guess we'll have to wait and see... for all we know, the current memory interface on AMD might not actually be able to manage feeding quad cores any better than Intel's FSB does.
Viditor - Sunday, April 1, 2007 - link
Actually, it appears (at least from the stuff I've seen so far) that the only apps that aren't effected by the bottleneck are the ones that are just as good on a dual core...in other words they don't scale well.
I agree with the AMD exec who intimated that AMD made a HUGE mistake in not coming out with an MCM quad chip in November...I think that the benches would have been nicely into the Opteron side of things well before Barcelona, but of course only on the quad chip.
I absolutely agree...I've been saying for the last year that AMD will most likely retake the lead again (even against Penryn), but that Nehalem is a whole nother ballgame...
I suppose that's possible, but if it were true then I think every executive at AMD would have dumped all of thier shares by now. :)
That's just as valid as saying it's possible that there's a flaw in Penryn when it gets over 2.8 GHz...possible, but I strongly doubt it.
TA152H - Monday, April 2, 2007 - link
I'm not sure why you guys don't think an increase in FSB and memory bandwidth (i.e. 1600) isn't going to help. It's seems beyond obvious it will. Will it help enough is the only question.With regards to the 2+2 from Intel, why does anyone really care? In some ways it's better than a true four in that you can clock them higher because you can pick pairs that make the grade, instead of hoping that all four core can clock really high. If one of the four can't, well, the whole thing has to be degraded. With Intel's approach, if one set of the cores is not capable at a certain speed, you just match it with one that is fairly close to it and sell it like that. It allows them to clock higher, and sell them less expensively than they would if they made a big quad-core die. The performance is excellent too, so it's a pretty good solution.
Why would AMD not have problems with Quad-Cores similar to Intel? You still have four cores sucking data through one memory bus, right? Or am I missing something? Is AMD going to have a memory bus for each core? That seems strange to me, so I'm going to assume they are not. The memory controller and point to point bus don't fundamentally change that problem. This comparison was fairly grotesque in that it made the memory subsystem for the Opteron seem better than it was. You had eight processors, yes, but only two cores since you had four sockets and only two cores were fighting for the same bus since you had a point to point. That's the advantage. If you have more sockets, the AMD solution will scale better, although NUMA has horrible penalties when you leave the processors own memory. If you add more processors to the same socket, you still have fundamentally the same problem, and point to point really isn't going to change that. You have four processors hitting the same bus either way.
With regards to FSB, remember it's also the reason why Intel processors have more cache. It's not a coincidence Intel processor have more cache, it's because AMD uses so much room on the processor for the memory controller. Intel decided they'd rather use the transistors for other things. I'm not speculating either, Intel has actually said this. Intel could have added a memory controller a long time ago, but they didn't. In fact, in the mid 1990s there was a company called NexGen (which AMD bought because they couldn't design a decent processor from scratch at the time, and had a lot of problems with the K5 that alienated companies like Compaq) which had an onboard memory controller with the NX586. Jerry Sanders decided to can it for the NX686 and use a standard Socket 7 platform instead of NexGen's proprietary one for what became the K6. The K6-III+ is a really interesting chip, you can actually change the multiplier on the fly without rebooting (I still use it for some servers, for exactly that reason).
Viditor - Monday, April 2, 2007 - link
Certainly it will help...but keep this in mind (going towards your question at the end):
1. Both this review and the one Johan did show the old K8 clearly doing as well or better than C2D across the board already (with 4 cores or more)...and Johan's numbers were on an Opteron using very old PC2700 memory as well (Jason and Ross didn't list their memory type).
2. While Barcelona will be HT 2.0, it will be the last one at this speed...the rest of the K10s (the ones that Penryn will be competing with) will be HT 3.0. In other words, while the FSB of Penryn systems will be raised from 1333 to 1600, the K10s will be going from 1 GHz to between 1.8 and 2.6 GHz...
Mainly because of the way it effects Intel's interchip communication. Remember that as apps become more parallel, they also require more communication between the cores. One of the great advances in C2D was the shared cache, the other was the Benseley platform (individual connections to the MCH). However, with an MCM quad core, the only path for one half of the chip to talk to the other half is through the FSB (MCH). In essence, you have 2 caches (each DC has a single cache, and there are 2 DC per CPU) per MCH connection, so we are back to a shared FSB again (in fact 2 shared FSBs). This recreates the bottleneck that the shared cache and Benseley were designed to get rid of...
Ummm...that's not how they manufacture their chips (and it would be outrageously expensive to do so!). The testing occurs after the cores have been placed on the chip...
Yes, you are...
Firstly is the interchip communication I spoke of. HT allows for direct connections between the caches of different chips, and the chips themselves have the cache directly connected on-die through a dedicated internal bus. That bus has 2 memory controllers connected directly to system memory as well as it's own dedicated HT connection (called cHT) to other caches. Remember that contrarily, Intel must route everything through the single MCH...
Actually, the reason Intel gave for not having an on-die memory controller is that memory standards change too quickly. But what they didn't say is that it takes many years (about 5 on average) to design and release a new chip, and an on-die memory controller is a major architectual change. That's why we don't see it on C2D, but we will see it on Nehalem...