The Intel Xeon W Review: W-2195, W-2155, W-2123, W-2104 and W-2102 Tested
by Ian Cutress & Joe Shields on July 30, 2018 1:00 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Workstation
- ECC
- Skylake-SP
- Skylake-X
- Xeon-W
- Xeon Scalable
Benchmarking Performance: CPU System Tests
Our first set of tests is our general system tests. These set of tests are meant to emulate more about what people usually do on a system, like opening large files or processing small stacks of data. This is a bit different to our office testing, which uses more industry standard benchmarks, and a few of the benchmarks here are relatively new and different.
All of our benchmark results can also be found in our benchmark engine, Bench.
FCAT Processing: link
One of the more interesting workloads that has crossed our desks in recent quarters is FCAT - the tool we use to measure stuttering in gaming due to dropped or runt frames. The FCAT process requires enabling a color-based overlay onto a game, recording the gameplay, and then parsing the video file through the analysis software. The software is mostly single-threaded, however because the video is basically in a raw format, the file size is large and requires moving a lot of data around. For our test, we take a 90-second clip of the Rise of the Tomb Raider benchmark running on a GTX 980 Ti at 1440p, which comes in around 21 GB, and measure the time it takes to process through the visual analysis tool.

FCAT likes single threaded performance, whcih shows the high frequency parts with faster memory near the top.
Dolphin Benchmark: link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in minutes, where the Wii itself scores 17.53 minutes.
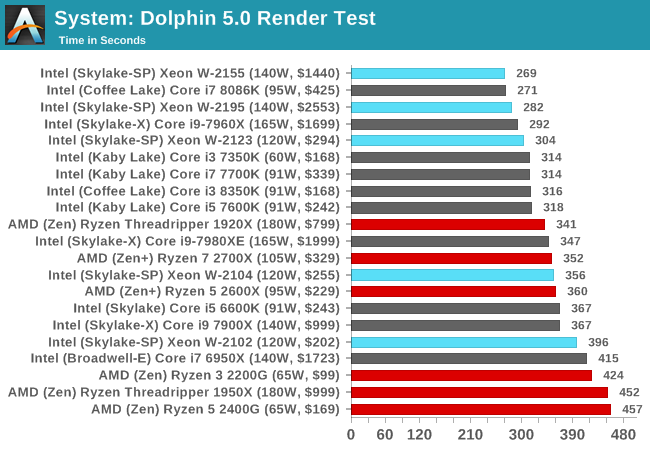
Dolphin is also pure ST frequency driven, however a surprise twist in that our Xeon W-2155 beats the Core i7-8086K in this test, although with a margin of error.
3D Movement Algorithm Test v2.1: link
This is the latest version of the self-penned 3DPM benchmark. The goal of 3DPM is to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in. It affords a ~25% speed-up over v2.0, which means new data.
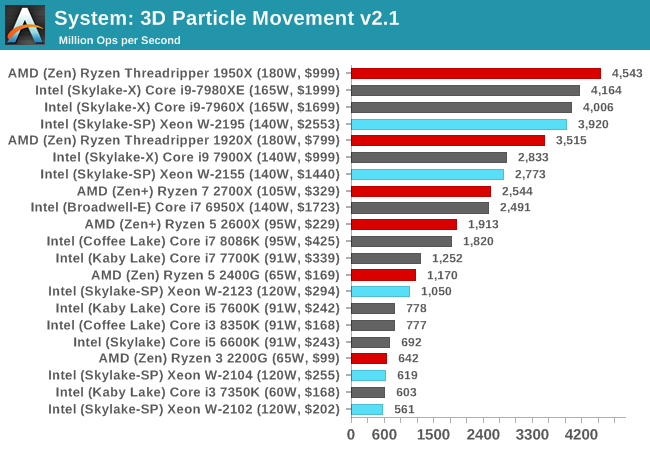
3DPM likes fast cache and frequency, and the W-2195 is almost fighting with the Core i9-7980XE here, and is let down slightly by its slow memory. The 1950X is still top dog.
DigiCortex v1.20: link
Despite being a couple of years old, the DigiCortex software is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation. The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
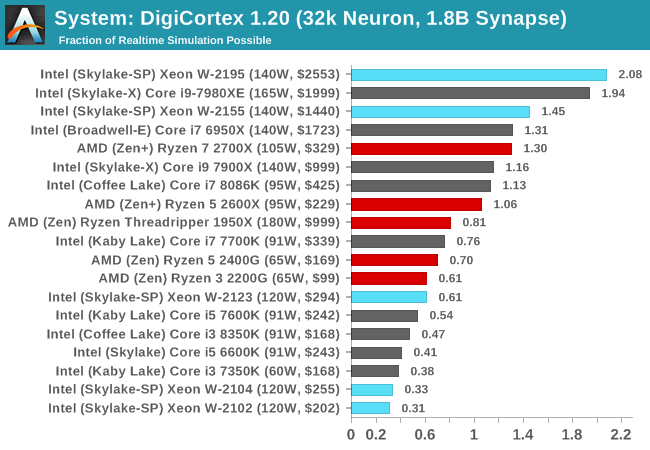
DigiCortex is a memory focused benchmark, but can also take advantage of AVX2 and sometimes AVX512, hence why the W-2195 is sat at the top. That being said, it is above the i9-7980XE, despite the latter having dual AVX512 ports.
Agisoft Photoscan 1.3.3: link
Photoscan stays in our benchmark suite from the previous version, however now we are running on Windows 10 so features such as Speed Shift on the latest processors come into play. The concept of Photoscan is translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the model. The algorithm has four stages, some single threaded and some multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.

Agisoft is a mixture of workloads, although the big multithreaded bit in the middle tends to dominate. Both the W-2195 and W-2155 score the same time, with a cluster of results around it. The Core i9-7960X sits on top though, with a seemingly better mix of cores and threads.








74 Comments
View All Comments
HStewart - Monday, July 30, 2018 - link
I am curious why Xeon W for same core count is typically slower than Core X - also I notice the Scalable CPU have much more functionally especially related to reliability. In essence to keep the system running 24/7. Also the Scalable CPU's also appear to have 6 channel memory instead of 4 Channel memory. I wonder when 6 channel memory comes to consumer level CPUs.One test that would be is to see what same core processor for Xeon W vs the Scalar CPU with only one CPU.
Another test that could be interesting is a dual CPU scalable with say 2 12 cores verses 1 24 core of CPU on same level.
Just test to see what it with more cores vs CPU's
duploxxx - Monday, July 30, 2018 - link
one threadripper 2.0 and you can throw all intel configs here into the bintricomp - Monday, July 30, 2018 - link
YeaHHStewart - Monday, July 30, 2018 - link
I wish people keep the topic to the subject and not blab about competitor productsduploxxx - Tuesday, July 31, 2018 - link
if you would know anything about cpu scalable systems you would not ask these questions. a 2*12 vs 1*24 will be roughly 20% slower if your application scales cross the total core count due to in between socket communication. Even Intel provides data sheets on that. No need to test.as long as intel can screw consumers they will not invest anything, you wont get 6 mem lanes in xeon W or consumer unless competition does it and they get nailed. btw why on earth would you need that on a consumer platform?
BurntMyBacon - Tuesday, July 31, 2018 - link
If all things are equal, then what you say is true. There is a known performance drop due to intersocket communications. However, you may have more TDP headroom (depends on the chips you are using) and mostly likely more effective cooling with two sockets allowing for higher frequencies with the same number of active cores. If the workload doesn't require an abundance of socket to socket communications, then it is conceivable that the two socket solution may have merit is such circumstances.SanX - Tuesday, July 31, 2018 - link
Why ARM is just digging its buggers watching the game where it can beat Intel ? Where are ARM server and supercomputer chips? ARM processors soon surpass Intel in transistor count. And for the same amount of transistors ARM is 50-100x cheaper then duopoly Intel/AMD. As an additional advantage for ARM these two segments will soon completely abandon Microsoft.beggerking@yahoo.com - Thursday, August 2, 2018 - link
ARM is RISC which is completely from CISC so applications and os are limited. Microsoft server os has really evolved in every aspect in the last few years that may take RISC years to catch up on the software side.JoJ - Saturday, August 4, 2018 - link
ARM is Fujitsu's choice of successor core to SPARC64+, a architecture Fujitsu invested decades of research and development and testing to offer both commercially and at a national laboratory supercomputing level. ARM is therefore not a knee jerk choice of direction for a very interesting super builder.Obviously you exaggerated a little bit, saying ARM is "50 - 100 times cheaper than AMD/Intel".
I wish I could shake my belief that pedantic literalism in Internet forums in general wasn't preventing broad discussion - we exaggerate in real life without any socially degrading effects, why not online?
OR ate your conversation parties sniffing that obviously -- any person who inadvertently speaks technically inaccurately despite forming perfectly understandable inquiry... as if they are unwashed know nothings, and turning on their heels to end the discussion.....a bit like HN's "we don't tolerate humor here" reactions to innocent attempts at lightening the thread...
but I digress, my point here is your comment above raised a couple of interesting questions, that I feel haven't been answered only because I think readers by themselves first over react to hyperbole, then infil the accepted wisdom to answer your questions, despite you ask about pertinent value critical concerns. I feel that by supplying the answer and dismissing the comment as uninformed, the most important thing happening is the reader voluntarily self reinforcing given marketing positions, and not engaging with the subject at all. I work in advertisingand am actually studying this, because advertising buyers adore this kind of"mind share" but we think that is at odds with the advertising buyers wanting"open minded, engaging, adaptable, innovative" customers.
1. have a look at Serve The Homes review of the Cavium ARM server generations. This architecture is definitely viable and competitive now in a increasing number of application areas.
2. Microsoft Azure has ARM deployed in my estimation at scale second only to Baidu. I am tempted to think it's actually politics that prevents a ARM Azure server machine offering to commercial users, little else. The problem with Microsoft, is user expectation of a all round performance consistency and intel and Microsoft have been working on that smooth delivery for decades.
3. ARM is bit cheaper if you need to do more than a quick recompile with a few architecture options selected.
re when we will see a Azure ARM instance, I think could even be waiting for the ability for Cavium to actually deliver hardware, because unmet demand is a fatal blow to new technology, as well as successful realisation.
All my"quality time" with our server fleet, is spent all hands on the thermal and power profiles of our applications.
We will rewrite to gain fractions of a percentage point where it's a consistent number across runs. Since twenty five years ago, I crashed a colo cage by not considering the power on start surge of a huge half terabyte raid array, power loads obsessed me. Power usage in Cavium ARM looks like a winner for us.
4. BUT I said that,based on data mapping dense thermal sensor arrays, with the functional code paths of the actual application logic in flight across the fleet, at the time. If we're able to calculate the cost benefit of routing a new application function to a specific server, depending on the thermal load and core behaviour at the time of dispatch, I admit we're not very typical for a small scale customer. I think small is a server count below 10,000 here, including any peak on demand usage in case you're consumer retail and sell half price Gucci shoes on Black Monday.
(we got surprised by the reliability of gains from very crude information. Originally we just wanted to see if we could balance the flows in the hot aisle, and even throttle hotspot buildup if we lost some cooling locally. For Intel, we got lots of gains, by sending jobs to not exceed the optimal max turbo clock of a processor, and immediately filling out the slower cores with background chores. AMD and Cavium ARM are not as sophisticated about thermal management, where Intel is keen on overkill recently, eg four nigh identical Xeon Gold SKUs. Just do really read that STH review about this"redundancy of the Xeon processor parts- I came away with a purchase order for the reviewed SKU, because we're so excited about the power management system roles in production deployment, as a competitive advantage.
5. REAL COST ADVANTAGE DEPENDS ON CHANNEL PENETRATION, WITH AMD AT 2%, yes, TWO percent is considered healthy for them today, AMD need to be shipping in far greater volume, to move the money dial to realise the kind of cost advantage SanX is excited about.
Certification of countless applications is hardly begun...
I want to use a ARM workstation, to eat my dog food. This necessitates nvidia Quadro cards support. Yes, I write for a living. I target CUDA for a ever increasing proportion of customer needs. SURE I can just remote machines at will. BUT IF YOU DON'T GIVE CRITICAL DEVELOPERS TRULY GREAT HARDWARE, YOU'RE ABANDONING THE PLATFORM FOR ANY IDEA OF GENERAL DEPLOYMENT.
6. Probably the last sentence should have been standalone here.
I'll just say that we need a workstation as cool as the Silicon Graphics Indy of'93, to get a chance of getting a new GENERAL purpose platform in the mainstream soon.
7. I am constantly a both astounded by the simple fact that we have a chip that good to compete at all, yet scared because I am starting to wonder if we'll ever see sales above"bargaining power level" and platform insurance, and the niche market for companies able to extract whole value chains from controling their entire software ecosystem, something almost nobody in the real world can do.
JoJ - Saturday, August 4, 2018 - link
typo, mea,in point 3, I mean to say, "ARM is NOT cheaper, if you need to do more than a quick recompile.."