AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
The Core Complex, Caches, and Fabric
Many core designs often start with an initial low-core-count building block that is repeated across a coherent fabric to generate a large number of cores and the large die. In this case, AMD is using a CPU Complex (CCX) as that building block which consists of four cores and the associated caches.
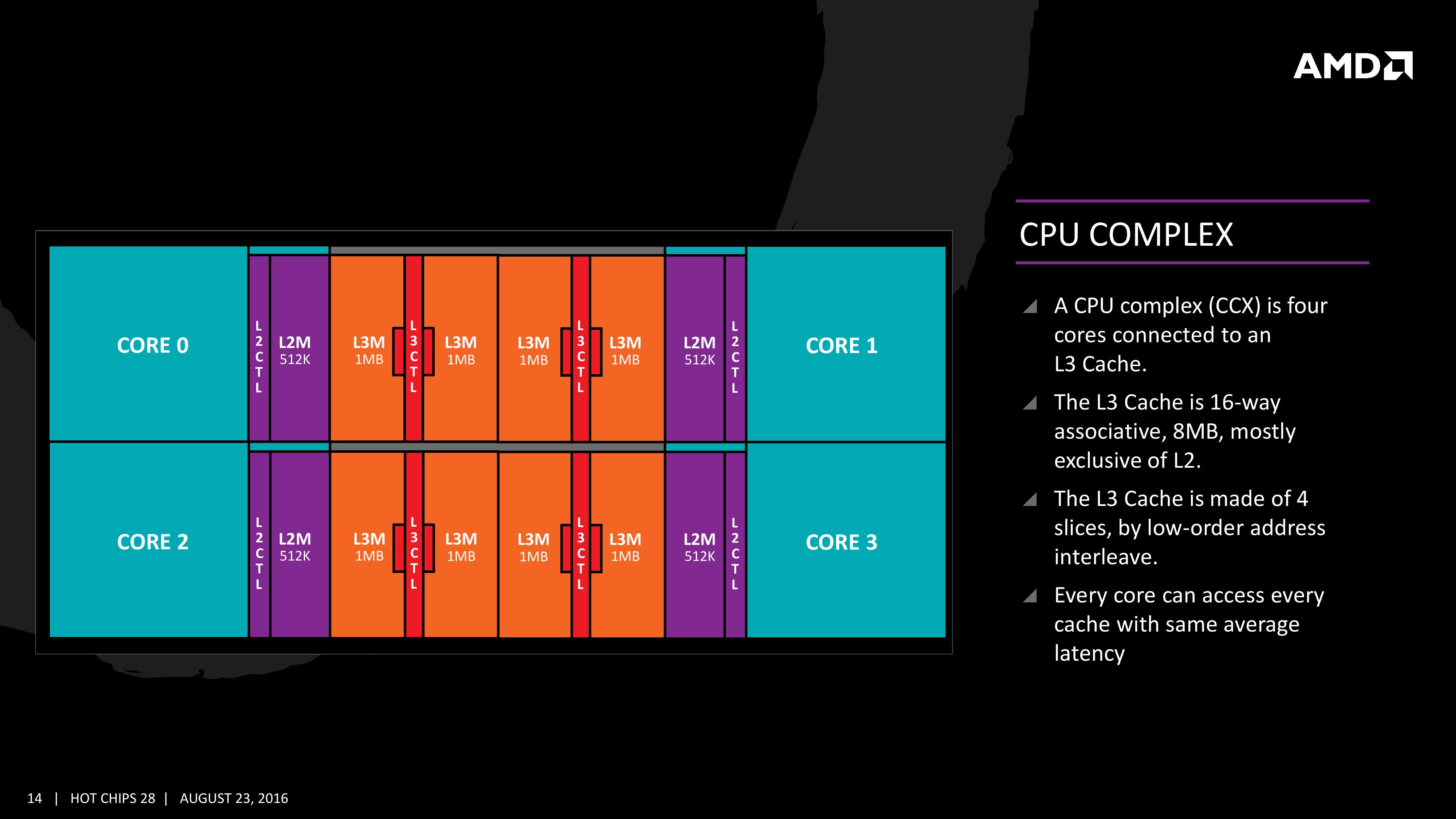
Each core will have direct access to its private L2 cache, and the 8 MB of L3 cache is, despite being split into blocks per core, accessible by every core on the CCX with ‘an average latency’ also L3 hits nearer to the core will have a lower latency due to the low-order address interleave method of address generation.
The L3 cache is actually a victim cache, taking data from L1 and L2 evictions rather than collecting data from prefetch/demand instructions. Victim caches tend to be less effective than inclusive caches, however Zen counters this by having a sufficiency large L2 to compensate. The use of a victim cache means that it does not have to hold L2 data inside, effectively increasing its potential capacity with less data redundancy.
It is worth noting that a single CCX has 8 MB of cache, and as a result the 8-core Zen being displayed by AMD at the current events involves two CPU Complexes. This affords a total of 16 MB of L3 cache, albeit in two distinct parts. This means that the true LLC for the entire chip is actually DRAM, although AMD states that the two CCXes can communicate with each other through the custom fabric which connects both the complexes, the memory controller, the IO, the PCIe lanes etc.
One interesting story is going to be how AMD’s coherent fabric works. For those that follow mobile phone SoCs, we know fabrics and interconnects such as CCI-400 or the CCN family are optimized to take advantage of core clusters along with the rest of the chip. A number of people have speculated that the fabric used in AMD’s new design is based on HyperTransport, however AMD has confirmed that they are not using HyperTransport here for Zen. More information on the fabric may come out as we nearer the launch, although this remains one of the more mysterious elements to the design at this stage.
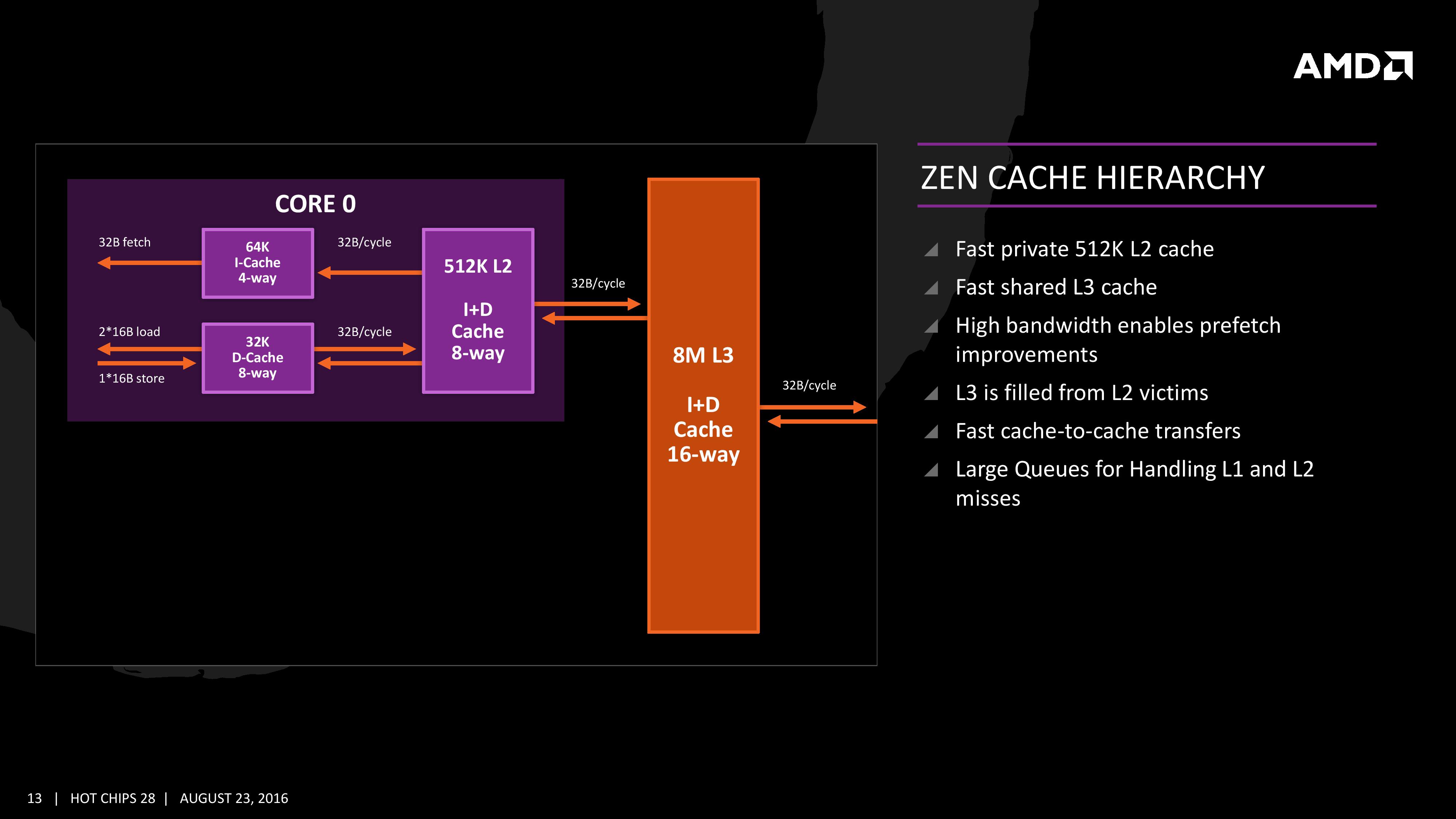
The cache representation in the new presentation at Hot Chips is almost identical to that in midweek, showing L1 and L2 in the core with 8MB of L3 split over several cores. AMD states that the L1 and L2 bandwidth is nearly double that of Excavator, with L3 now up to 5x for bandwidth, and that this bandwidth will help drive the improvements made on the prefetch side. AMD also states that there are large queues in play for L1/L2 cache misses.








106 Comments
View All Comments
CrazyElf - Tuesday, August 23, 2016 - link
If they can really get a 40% improvement over Excavator, and I mean 40% on average, not on a few select benchmarks, then AMD has a serious chance of being a compelling option once again.I'm hoping to see more improvements on Floating Point, which was comically bad in Bulldozer.
A big part of the problem is that we don't know how well Zen will clock or the power consumption. Still, this should be a major leap in performance overall. We'll have to wait for the launch day benchmarks to see the true story.
Another big concern is the platform. CPU performance is only part of the story. We need a good platform that can rival the Z170 and Intel HEDT platforms for this to be compelling on the desktop. For mobile, there will have to be good dual channel Zen APUs (Carrizo, as Anandtech noted was heavily gimped by poor quality OEM designs obsessed with cost cutting).
jabber - Wednesday, August 24, 2016 - link
Yeah I don't think OEMs and others are that worried about supporting AMD. AMD have withered away so much, making AMD CPU capable gear must have become a very minor part of say ASUS/Gigabyte/MSI etc. revenue stream. Making AMD based graphics cards is okay but motherboards? Not so much.teuast - Wednesday, August 24, 2016 - link
I wouldn't speak so soon. Just this year MSI and Gigabyte (at least) have introduced new AM3+ boards with USB 3.1 and PCIe 3.0. Why, I'm not sure, but if they're doing that for something as old and deprecated as the FX chips, it would defy logic for Zen to come out and for them to only release a few token efforts.I will say, if the CPUs are good but you're right about OEMs not being concerned with support, then the first OEM to say "hey, why don't we make some actually good AM4 boards?" is going to make an absolute killing.
h4rm0ny - Thursday, August 25, 2016 - link
Are you sure about the PCI-E v3 on AM3+ motherboards? I can find recent releases that have USB3.1 and M.2, but none that support PCI-Ev3. Can you link me or provide a model number? I didn't think 3rd generation PCI-E was possible on the Bulldozer line.SKD007 - Thursday, August 25, 2016 - link
SABERTOOTH 990FX/GEN3 R2.0SKD007 - Thursday, August 25, 2016 - link
https://www.asus.com/Motherboards/SABERTOOTH_990FX...Outlander_04 - Thursday, August 25, 2016 - link
A little misleading . The Graphics pci-e controller is built in to an FX processor so adding a pci-e 3 standard slot to a motherboard will make no difference to actual bandwidth.Not an issue though since x16 pci-e 2 has the same bandwidth as x8 pci-e 3 and intel boards with SLI/crossfire ability running at x8/x8 do not choke any current graphics card
h4rm0ny - Thursday, August 25, 2016 - link
What about PCI-E SSDs? Can I get full bandwidth on those? I agree about the graphics cards but that's not so important to me. If I can get full PCI-Ev3 x4 performance for an SSD then I'll pribably buy this as a hold-over until Zen. Thanks fir the link!fanofanand - Friday, August 26, 2016 - link
Pci-e 3.0 x4 should be the same as 2.0 x 8. So long as you have a vacant x8 it should theoretically work the same.extide - Wednesday, September 7, 2016 - link
I think they use a PLX chip and turn the 32 2.0 lanes from the FX chip into 16 3.0 lanes.