Original Link: https://www.anandtech.com/show/3972/nvidia-gtc-2010-wrapup
Today we’re wrapping up our coverage of last month’s NVIDIA GPU Technology Conference, including the show’s exhibit hall. We came to GTC to get a better grasp on just where things are for NVIDIA's still-fledging GPU compute efforts along with the wider industry as a whole, and we didn’t leave disappointed. Besides seeing some interesting demos – including the closest thing you’ll see to a holodeck in 2010 – we had a chance to talk to Adobe, Microsoft, Cyberlink, and others about where they see GPU computing going in the next couple of years. The GPU-centric future as NVIDIA envisioned it may be taking a bit longer than we hoped, but it looks like we may finally be turning the corner on when GPU computing breaks in to more than just the High Performance Computing space.

Scalable Display Technologies’ Multi-Projector Calibration Software: Many Projectors, 1 Display
Back in 2009 when we were first introduced to AMD’s Eyefinity technology by Carrell Killebrew, he threw out the idea of the holodeck. Using single large surface technologies like Eyefinity along with video cards power enough to render the graphics for such an experience, a holodeck would become a possibility in the next seven years, when rendering and display technologies can work together to create and show a 100 million pixel environment. The GPUs necessary for this are still years off, but it turns out the display technologies are much closer.
One of the first sessions we saw at GTC was from Scalable Display Technologies, a MIT-spinoff based in Cambridge, MA. In a session titled Ultra High Resolution Displays and Interactive Eyepoint Using CUDA, Scalable discussed their software based approach to merging together a number of displays in to a single surface. In a nutshell, currently the easiest way to create a single large display is to use multiple projectors to each project a portion of an image on to a screen. The problem with this approach is that calibrating projectors is a time-consuming process, as not only do they need to be image-aligned, but also care must be taken to achieve the same color output from each projector so that minute differences in projectors do not become apparent.
Scalable however has an interesting solution that does this in software, relying on nothing more on the hardware side than a camera to give their software vision. With a camera in place, their software can see a multi-projector setup and immediately begin to calibrate the projectors by adjusting the image sent to each projector, rather than trying to adjust each projector. Specifically, the company is taking the final output of a GPU and texture mapping it to a mesh that they then deform to compensate for the imperfections the camera sees, and adjusting the brightness of sections of the image to better mesh together. This rendered mesh is used as the final production, and thanks to the use of intentional deformation, it cancels out the imperfections in the projector setup. A perfect single surface, corrected in the span of 6 seconds versus minutes and hours for adjusting the projectors themselves.


Along with their discussion of their technology, GTC Scalable is showing off a custom demonstration unit using 3 720P projectors to project a single image along a curved screen. Why curved? Because their software can correct for both curved and flat screens, generating an image that is perspective-correct even for a curved screen. The company also discussed some of the other implementations of their technology, where as it turns out their software has been used to build Carrell’s holodeck for a military customer: a 50 HD projector setup (103.6MPixels) used in a simulator, and kept in calibration with Scalable’s software. Ultimately Scalable is looking to not only enable large projection displays, but to do so cheaply: with software calibration it’s no longer necessary to use expensive enterprise-grade projectors, allowing customers to use cheaper consumer-grade projectors that lack the kind of hardware calibration features this kind of display would normally require. Case in point, their demo unit uses very cheap $600 projectors. Or for that matter it doesn’t even have to be a projector – their software works with any display type, although for the time being only projectors have the ability to deliver a seamless image.
Wrapping things up, we asked the company about whether we’d see their software get used in the consumer space, as at the moment it’s principally found in custom one-off setups for specific customers. The long and the short answer is that as they’re merely a software company, they don’t have a lot of control over that. It’s their licensees that build the final displays, so one of them would need to decide to bring this to the market. Given the space requirements for projectors it’s not likely to replace the multi-LCD setup any time soon, but it’s a good candidate for the mancave, where there would be plenty of space for a triple-projector setup. We’ve already seen NVIDIA demonstrate this concept this year with 3D Vision Surround, so there may very well be a market for it in the consumer space.
Micoy & Omni-3D
The other company on hand showing a potential holodeck-like technology was Micoy, who like Scalable is a software firm. Their focus is on writing the software necessary to properly build and display a 3D environment on an all-encompassing (omnidirectional) view such as a dome or CAVE, as opposed to 3D originating from a 2D surface such as a monitor or projector screen. The benefit of this method is that it can encompass the entire view of the user, eliminating the edge-clipping issues with placing a 3D object above-depth of the screen; or in other words this makes it practical to render objects right in front of the viewer.
At GTC Micoy had an inflatable tent set up, housing a projector with a 180° lens and a suitable screen, which in turn was being used to display a rolling demo loop. In practice it was a half-dome having 3D material projected upon it. The tent may have caught a lot of eyes, but it was the content of the demo that really attracted attention, and it’s here where it’s a shame that pictures simply can’t convey the experience, so words will have to do.

I personally have never been extremely impressed with 3D stereoscopic viewing before – it’s a nice effect in movies and games when done right, but since designers can’t seriously render things above-depth due to edge-clipping issues it’s never been an immersive experience for me. Instead it has merely been a deeper experience. This on the other hand was the most impressive 3D presentation I’ve ever seen. I’ve seen CAVEs, OMNIMax domes, 3D games, and more; this does not compare. Micoy had the honest-to-goodness holodeck, or at least the display portion of it. It was all-encompassing, blocking out the idea that I was anywhere else, and with items rendered above-depth I could reach out and sort-of touch them, and other people could walk past them (at least until they interrupted the projection). To be quite clear, it still needs much more resolution and something to remedy the color/brightness issues of shutter glasses, but still, it was the prototype holodeck. When Carrell Killebrew talks about building the future holodeck, this is no doubt what he has in mind.
I suppose the only real downside is that Micoy’s current technology is a tease. Besides the issues we listed earlier, their technology currently doesn’t work in real-time, which is why they were playing a rolling demo. It’s suitable for movie-like uses, but there’s not enough processing power right now to do the computation required in real-time. It’s where they want to go in the future, along with a camera system necessary to allow users to interact with the system, but they aren’t there yet.
Ultimately I wouldn’t expect this technology to be easily accessible for home-use due to the costs and complexities of a dome, but in the professional world it’s another matter. This may very well be the future in another decade.
HPC: Dell Says a Single PCIe x16 Bus Is Enough for Multiple GPUs – Sometimes
One of the more interesting sessions we saw was a sold-out session being held by Dell, discussing whether a single PCIe x16 bus provides enough bandwidth to GPUs working on HPC tasks. Just as in the gaming world, additional x16 busses come at a premium, and that premium doesn’t always offer the kind of performance that justifies the extra cost. In the case of rackmount servers, giving each GPU a full x16 bus either means inefficiently packing GPUs and systems together by locating the GPU internally with the rest of the system, or running many, many cables from a system to an external cage carrying the GPUs. Just as with gaming, if you can get more GPUs to share a PCIe bus then the cheaper it becomes. While for gaming this means using cheaper chipsets, for servers this means being able to run more GPUs off of a single host system, reducing the number of hosts an HPC provider would need to buy.
Currently the most popular configurations for the market Dell competes in are systems with a dedicated x16 bus for each GPU, and systems where 2 GPUs share an x16 bus. Dell wants to push the envelope here, and go to 4 GPUs per x16 bus in the near future, and upwards of 8 and 16 GPUs per bus in the far future when NVIDIA enables support for that in their drivers. To make that happen, Dell is introducing the PowerEdge C410x PCIe Expansion Chassis, a 3U chassis capable of holding up to 16 GPUs. Their talk in turn what about what they found when testing this cassis when filled with Tesla 1000 series cards (GT200 based) in conjunction with a C410 server.
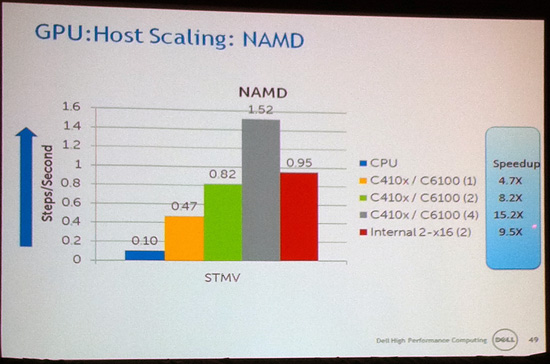
Ultimately Dell’s talk, delivered by staff Ph.D Mark R. Fernandez, ended up being an equal part about the performance hit of sharing a x16 bus, and whether the application in question will scale with more GPUs in the first place. Compared to the gold standard of one bus per GPU and internally locating the GPUs, simply moving to an external box and sharing an x16 bus among 2 GPUs had a negative impact in 4 of the 6 applications Dell tested with. The external connection would almost always come with a slight hit, while the sharing of the x16 bus is what imparted the biggest part of the performance hit as we would expect.
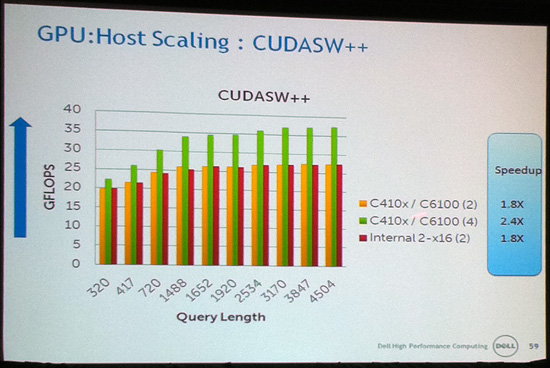
However when the application in question does scale beyond 1-2 GPUs, what Dell found was that the additional GPU performance more than offset the loss through a shared bus. In this case 4 of the same 6 benchmarks saw a significant performance improvement in moving from 2 to 4 GPUs; ranging between a 30% improvement and a 90% improvement. With these many GPUs it’s hard to separate the effects of the bus from scaling limitations, but it’s clear there’s a mix of both going on, in what seems particularly dependent on just how much bus chatter an application eventually causes.
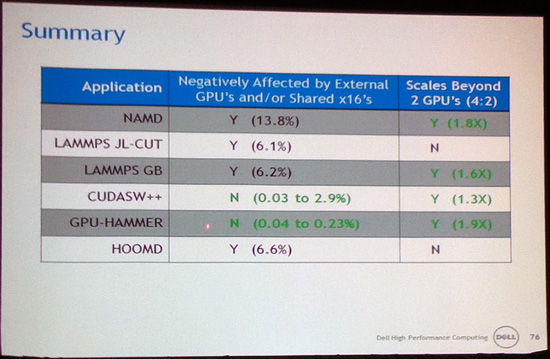
So with these results, Dell’s final answer over whether a single x16 PCIe bus is enough was simply “sometimes”. If an application scales against multiple GPUs in the first place, it usually makes sense to go further – after all if you’re already on GPUs, you probably need all the performance you can get. However if it doesn’t scale against multiple GPUs, then the bus is the least of the problem. It’s in between these positions where the bus matters: sometimes it’s a bottleneck, and sometimes it’s not. It’s almost entirely application dependent.
NVIDIA Quadro: 3D for More than Gaming
While we were at GTC we had a chance to meet with NVIDIA’s Quadro group, the first such meeting since I became AnandTech’s Senior GPU Editor. We haven’t been in regular contact with the Quadro group as we aren’t currently equipped to test professional cards, so this was the first step in changing that.
Much of what we discussed we’ve already covered in our quick news blurb on the new Quadro parts launching this week: NVIDIA is launching Quadro parts based on the GF106 and GF108 GPUs. This contrasts from their earlier Fermi Quadro parts, which used GF100 GPUs (even heavily cut-down ones) in order to take advantage of GF100’s unique compute capabilities: ECC and half-speed double precision (FP64) performance. As such the Quadro 2000 and 600 are more focused on NVIDIA’s traditional professional graphics markets, while the Quadro 4000, 5000, and 6000 cover a mix of GPU compute users and professional graphics users who need especially high performance.

NVIDIA likes to crow about their professional market share, and for good reason – their share of the market is much more one-sided than consumer graphics, and the profit margins per GPU are much higher. It’s good to be the king of a professional market. It also helps their image that almost every product being displayed is running a Quadro card, but then that’s an NV conference for you.
Along those lines, it’s the Quadro group that gets to claim much of the credit for the big customers NVIDIA has landed. Adobe is well known, as their Premiere Pro CS5 package offers a CUDA backend. However a new member of this stable is Industrial Light & Magic, who just recently moved to CUDA to do all of their particle effects using a new tool they created, called Plume. This is one of the first users that NVIDIA mentioned to us, and for good reason: this is a market they’re specifically trying to break in to. Fermi after all was designed to be a ray tracing powerhouse along with being a GPU compute powerhouse, and while NVIDIA hasn’t made as much progress here (the gold standard without a doubt being who can land Pixar), this is the next step in getting there.

Finally, NVIDIA is pushing their 3D stereoscopy initiative beyond the consumer space and games/Blu-Ray. NVIDIA is now looking at ways to use and promote stereoscopy for professional use, and to do so they cooked up some new hardware to match the market in the form of a new 3D Vision kit. Called 3D Vision Pro, it’s effectively the existing 3D Vision kit with all Infrared (IR) communication replaced with RF communication. This means the system uses the same design for the base and the glasses (big heads be warned) while offering the benefits of RF over IR: it doesn’t require line of sight, it plays well with other 3D Vision systems in the same area, and as a result it’s better suited for having multiple people looking at the same monitor. Frankly it’s a shame NVIDIA can’t make RF more economical – removing the LoS requirements alone is a big step up from the IR 3D Vision kit where it can be easy at times to break communication. But economics is why this is a professional product at the time: the base alone is $399, and the glasses are another $349, a far cry from the IR kit’s cost of $199 for the base and the glasses together.
Microsoft’s Next RDP Moves Rendering Back to the Server
As the architects & overseers of DirectX, we mention Microsoft and GPUs together quite often when talking about the consumer aspects of their technology. But the company was also at GTC to discuss how GPUs factor in to their server plans. The major discussion they gave based on this theme was about the next version of Remote Desktop, version 7.1, which is going to have significant ramifications for how the protocol works, and when it comes to GPUs where the load is going to be.
For a quick bit of background, RDP was originally designed with a focus to be light on bandwidth usage – it accomplished this by having the server send rendering commands to the client rather than sending full frames. This worked very well in the 2D GDI days, where RDP’s underpinnings matched up rather well against how early video cards worked: a screen was really only composed of a handful of high-level commands, and the CPU (and later, GDI video cards) took care of rendering all of this. However this design wasn’t one that kept pace with the future very well; simple video cards became complex GPUs that were capable of quickly and effectively doing things like transparency on the desktop, playing back videos, and of course rendering many complex 3D items at once.
Ultimately in the 14 years since Windows NT 4.0 came out, passing data at a high level has become more tedious, and this has required that clients have GPUs whose capabilities were similar to what the remote desktop session wished to accomplish. Meanwhile the remote desktop concept (which is not in any way new) has seen a significant surge in popularity in recent years as x86 virtualization has matured, enticing companies to move to remotely hosted sessions running on virtualized hardware in order to improve their reliability and ease of client management. This in turn is a push towards a true thin client desktop where all the heavy lifting is done by the server, and the client is a dumb box (or tablet, or phone, or…) that displays things.
Because of these changes in the market, Microsoft’s chosen path of progression has been through what amounts to regression. RDP is a “smart” protocol intended to go light on bandwidth, but it requires a smart client to do the rendering. The solution Microsoft is pursing is to go dumb: instead of sending high-level commands, just stream the desktop outright. This nullifies RDP’s bandwidth savings, but it allows for truly thin clients that don’t need to be able to do anything other than decoding a video stream, and in the process it handily solves the problems with trying to use high-level commands to remotely render videos and complex 3D imagery. To use an analogy, this would be much closer to how VNC (open source remote desktop system) or OnLive (game streaming) work, as compared to RDP as it exists today.

The resulting desktop streaming software that Microsoft is developing is called RemoteFX, and it will be introduced as part of RDP 7.1 with Windows 2008 R2 SP1, which is due in early 2011. Microsoft has been developing it since 2008, when they acquired Calista Technologies who originally developed the technology.
By now a few of you are wondering what this has to do with GPUs, and it ultimately comes down to 1 thing: where the GPU needs to be. RemoteFX goes hand-in-hand with fully embracing a GPU-rendered desktop for remote users, which means the servers hosting these remote sessions – which previously never needed a real GPU - will now need GPUs to render all of these desktops. It’s a migration of sorts, as the clients will no longer use GPUs (at least not for anything more than video decoding) but the servers will. And this is the angle for GTC attendees, as business users looking to take advantage of RemoteFX now need to consider equipping their server farms with GPUs in order to handle the technology.
On the backend of things Microsoft is requiring DirectX 10-class GPUs, while the rendered desktop will be using DirectX 9. This is a bit of an odd combination, but it comes as a result of how RemoteFX works. Fundamentally RemoteFX will be hosting a graphical context for each remote desktop, rather than outright virtualizing the GPU in the traditional sense. In turn the virtualized copy of Windows will be running a video driver that emulates a DX9 GPU, the frontend of which exists as the graphical context running on the host. This is distinctly different from truly virtualizing the GPU as the virtualized instances of Windows do not have direct access to the GPU (ed: So no Folding@Home, guys), whereas a virtualized GPU would afford direct access while it shared the hardware.

Overall this ties in well to DirectX 10 and the associated driver changes, which were strongly focused on GPU context switching and scheduling so that multiple applications could more easily share a GPU. But for many of these same reasons (specifically: DX10 + WDDM is complex to emulate) the remote desktops themselves will be limited to DirectX 9 functionality, as that’s the capability Microsoft inherited with they purchased the software, and for the time being DX9 much easier to accomplish while Microsoft works out the complexities of a virtualized DX10 for future versions of the software.
As for the streaming video codec, Microsoft is making it quite clear that they’re not using an existing codec such as H.264 for this. Rather it will be based on a new codec optimized for very low latency encoding/decoding and for high quality text reproduction, with the goal being lossless quality when possible. Furthermore they want to move this all in to dedicated hardware to minimize power usage: clients would have this codec added to the capabilities of their existing video decode blocks, and servers would be given dedicated ASICs for encoding. The benefits of using dedicated hardware are clear as we’ve seen with Intel’s Sandy Bridge Media Engine – which achieves GPU-like encode performance in a 3mm2 piece of silicon – and Microsoft believes they have the clout to influence hardware designers in to including their codec in their products’ decode blocks. The decoder itself is royalty-free to sweeten the deal, and will likely be Microsoft’s strongest leverage in to getting support for it in to mobile products such as tablets and cell phones.

Finally, with Windows Server 2008 R2 SP1 shipping next year, Microsoft showed off a demo of RemoteFX in action. With a focus on where RDP fails, they played an HD video and then an IE9 GPU test over an RDP session which in turn was being run over a 100Mb network to a host a few feet away; in both cases RDP wasn’t capable of keeping up, and rendered things in terms of seconds per frame. On the same demo with RemoteFX, RemoteFX was able to keep up although we hesitate to call it perfectly smooth.
Ultimately we can’t help but notice that Microsoft has come full circle on the role of clients and servers. Microsoft was founded at the start of the microcomputer revolution, when computing was just moving away from mainframes and proto-servers, and now with RemoteFX they’re ensuring that all of that can be pushed back to the server. Over the years the roles of clients and servers has constantly swung between the two, and it looks like it’s swinging back to the server side in the near future (after which it will no doubt swing back the other way). For NVIDIA and AMD this means the companies will have a new focus on server infrastructure, as the importance of a client GPU gives way to the importance of a server GPU.
Memory: The Compatriot of the GPU
While GTC was a show built around NVIDIA’s GPUs, it’s more than just a GPU that makes up a video card. Both Samsung and Hynix had a presence at the show, the two of them being the principle suppliers of GDDR5 at the moment (while there are other manufacturers, every single card we have is Samsung or Hynix). Both companies recently completed transitions to new manufacturing nodes (40nm), and are now bringing up denser GDDR5 memory that they were at the show to promote.
First off was Samsung, who held a green-themed session about their low power GDDR5 and LPDDR2 products, primarily geared towards ODMs and OEMs responsible for designing and building finished products. The adoption rate on both of these product lines has been slow so far.

Starting with GDDR5, normally GDDR5’s specification calls for a 1.5v operating voltage, but Samsung also offers a line of “Green Power” GDDR5 which operates at 1.35v. Going by Samsung’s own numbers, dropping from 1.5v to 1.35v reduces GDDR5 power consumption by 33%. The catch of course is that green power GDDR5 isn’t capable at running at the same speeds as full power GDDR5, with speeds topping out at around 4Gbps. This makes green power GDDR5 unsuitable for cards such as the Radeon 5800 and 5700 series which use 5Gbps GDDR5, but it would actually make it a good fit for AMD’s lower end cards and all of NVIDIA’s cards, the latter of which never exceed 4Gbps. Of course there are tradeoffs to consider; we don’t know what Samsung is doing with respect to bank grouping on the green parts to hit 4Gbps, and bank grouping is the enemy of low latencies. And of course there’s price, as Samsung charges a premium for what we believe are basically binned GDDR5 dies.
The other product Samsung was quickly discussing was LPDDR2. We don’t delve on this too much, but Samsung is very interested in moving the industry away from LPDDR1 (and even worse, DDR3L) as LPDDR2 consumes less power than either. Samsung believes the sweet spot for memory pricing and performance will shift to LPDDR2 next year.
Finally, we had a chance to talk to Samsung about the supply of their recently announced 2Gbit GDDR5. 2Gbit GDDR5 will allow cards using a traditional 8 memory chip configuration to move from 1GB to 2GB of memory, or for existing cards such as the Radeon 5870 2GB, move from 16 chips to 8 chips and save a few dozen watts in the process. The big question right now with regards to 2Gbit GDDR5 is the supply, as tight supplies of 1Gbit GDDR5 was fingered as one of the causes of the limited supply and higher prices of Radeon 5800 series cards last year. Samsung tells us that their 2Gbit GDDR5 is in mass production and shipping, however the supply is constrained through the end of the year.
Moving on, as we stated earlier Hynix was also at GTC. Unlike Samsung they weren’t doing a presentation, but they did have a small staffed booth in the exhibition hall touting their products. Like Samsung their 2Gbit GDDR5 is in full production and officially is available right now. Currently they’re offering 2Gbit and 1Gbit GDDR5 up to 6Gb/sec (albeit at 1.6v, 0.1v over spec) which should give you an idea of where future video cards may go. Like Samsung it sounds like they have as much demand as they can handle at the moment for their 2Gbit parts, so supply may be tight for high speed 2Gbit parts for the rest of the year throughout the industry.

There was one other thing on the brochure they were handing out that we’d like to touch on: things reaching End of Life. In spite of the fact that the AMD 5xxx series and NVIDIA 4xx series cards all use GDDR5 or plain DDR3, GDDR3 is still alive and well at Hynix. While they’re discontinuing their 4th gen GDDR3 products this month, their 5th gen products live on to fill video game consoles and any remaining production of last-generation video cards. What is being EOL’d however is plain DDR2, which meets its fate this month. DDR3 prices have already dropped below DDR2 prices, and it looks like DDR2 is now entering the next phase of its life where prices will continue to creep up as it’s consumed as upgrades for older systems.
Scaleform on Making a UI for 3D Vision
One of the sessions we were particularly interested in seeing ahead of time was a session by Scaleform, a middleware provider that specializes in UIs. Their session was about what they’ve learned in making UIs for 3D games and applications, a particularly interesting subject given the recent push by NVIDIA and the consumer electronics industry for 3D. Producing 3D material is still more of a dark art than a science, and for the many of you that have used 3D Vision with a game it’s clear to see that there are some kinks left to work out.
The problem right now is that traditional design choices for UIs are built around 2D, which leads to designers making the implicit assumption that the user can see the UI just as well as the game/application, since everything is on the same focal plane. 3D and the creation of multiple focal planes usually results in the UI being on one focal plane, and often quite far away from the action at that, which is why so many games (even those labeled as 3D Vision Ready) are cumbersome to play in 3D today. As a result a good 3D UI needs to take this in to account, which means breaking design rules and making new ones.

Scaleform’s presentation focused both on 3D UIs for applications and for gaming. For applications many of their suggestions were straightforward, but were elements that required a conscientious effort of the developer, such as not putting pop-out elements at the edge of the screen where they can get cut off, and rendering the cursor at the same depth as the item it’s hovering over. They also highlighted other pitfalls that don’t have an immediate solution right now, such as being able to maintain the high quality of fonts when scaling them in a 3D environment.
As for gaming, their suggestions were often those we’ve heard from NVIDIA in the past. The biggest suggestions (and biggest nuisance in gaming right now) had to deal with where to put the HUD: painting a HUD at screen depth doesn’t work; it needs to be rendered at depth with the objects the user is looking at. Barring that it should be tilted inwards to lead the eye rather than being an abrupt change. They mentioned Crysis 2 of this as an example of this, as it has implemented its UI in this manner. Unfortunately for 2D gamers, it also looks completely ridiculous on a 2D screen, so just as how 2D UIs aren’t great for 3D, 3D UIs aren’t great for 2D.

Crysis 2's UI as an example of a good 3D UI
Their other gaming suggestions focused on how the user needs to interact with the world. The crosshair is a dead concept since it’s 2D and rendered at screen depth. Instead, taking a page from the real world, laser sights (i.e. the red dot) should be used. Or for something that isn’t first-person like an RTS, selection marquees need to map to 3D objects – whether items should be selected should be based upon how the user would see it rather than absolute position.
Cyberlink & Adobe: Views On Consumer GPU Computing
GTC is a professional show, but that doesn’t just mean it’s for professional software, or even consumer software for that matter. It’s also a show for professional software developers looking into how to better utilize GPUs in their products. This brought Adobe and Cyberlink to the show, and the two companies are the current titans of GPU computing in consumer applications. One of our major goals with GTC was to speak with each of them and to see what their expectations were for GPU computing in consumer applications in the future (something NVIDIA has heavily promoted for years), and we didn’t leave disappointed. In fact if anything we got some conflicting views, which showcases just where the use of GPU computing in consumer applications stands today.
We’ll start with Cyberlink, who was on hand to showcase their latest version of MediaExpresso (née, MediaShow Expresso), their GPU-powered video encoding suite. Tom Vaughan, their director of business development was on hand to show the software and answer our questions.
As it stands, Cyberlink develops products against both AMD’s Stream API and NVIDIA’s CUDA API, largely as a legacy of the fact that they’ve offered such products for a few years now when means they predate common APIs like OpenCL or DirectCompute. So our first questions were about the progress of these APIs, and where the company sees itself going with them.
Cyberlink is primarily a Windows company, so they're in a position where they can use either OpenCL or DirectCompute as they deem it necessary. They're already using DirectCompute for face detection in MediaShow (and this is the only commercial application using DirectCompute that we're aware of right now), although it sounds like the company is likely to do the bulk of their GPU computing work with OpenCL in the future. For products such as MediaShow Expresso, Tom believes that ultimately the company will end up using a single OpenCL codebase with a single codepath for the GPU acceleration of encoding and related features. From our perspective this is very forward-looking, as we are well aware that there are still issues with OpenCL for Cyberlink (or anyone else intent on shipping an OpenCL product) to deal with, such as issues to work out with the OpenCL drivers and the lack of a common ICD; and it doesn’t help that not everyone currently ships OpenCL drivers with their regular driver set.
Furthermore,, as Tom noted to us it's not in Cyberlink's best interests to immediately jump ship to DirectCompute or OpenCL for everything right away. As it stands there’s no good reason for them to reinvent the wheel by throwing out their existing work with CUDA and Stream, so those codebases could be in use for quite a while longer. New features will be written in OpenCL (when the drivers are ready), but for the time being the company is attached to CUDA/Stream for a while longer yet. But on that note, when they go to OpenCL they really do expect to have a single codebase, and will be running the same routines on both AMD and NVIDIA GPUs, as they believe it’s unnecessary to write optimized paths for AMD and NVIDIA even with the significant differences between the two companies’ GPU architectures.
![]()
In the wider viewer, Tom definitely sees additional companies finally getting in to GPU compute and for more things than just video encoding once the OpenCL driver situation stabilizes. I don’t believe Tom (or really anyone else) knows what else GPU computing is going to be used for in the consumer space, but it’s clear the groundwork for it is finally starting to come together. Truthfully we expected the OpenCL driver and application situation to be a great deal better more than a year after OpenCL was finalized, but it looks like that time is fast approaching.
The second group we talked to was Adobe, who was giving a session based around their experiences in shipping commercial software with GPU acceleration over the last 3 iterations of the Adobe Creative Suite. In Adobe’s case they’ve had GPU graphical acceleration since CS3, and CS5 added the first example of GPU compute acceleration with the CUDA-powered Mercury Engine in Premiere Pro CS5. Giving the talk was Kevin Goldsmith, the engineering manager of their Image Foundation group, who in turn provides the GPU-accelerated libraries the other groups use in their products.

Over the hour they listed a number of specific incidents they had, but there were a few common themes throughout the talk. The first was that they can’t ignore Intel’s CPUs or their GPUs; the latter because they are the #1 source of crashes for their GPU accelerated software, and the former because you have to rely on them when their GPUs aren’t stable or a suitable GPU simply isn’t available. In fact Kevin was rather frank about how Intel’s GPUs and drivers had caused them a great deal of grief, and that as a result they’ve had to blacklist a great deal of Intel product/driver combinations as the drivers advertise features that aren’t working correctly or aren’t stable. There was a very strong message that for the time being, any kind of GPU acceleration was really only viable on NVIDIA and AMD GPUs, which in turn is a much smaller market that requires that the company have CPU codepaths for everything they do with a GPU.
This lead in to a discussion on testing, which was the second common theme. The unfortunate reality is that GPUs are death to QA at the moment. CPU are easy to test against, and while the underlying OS can change it very rarely does so; meanwhile GPUs come far more often in far more varieties, and have a driver layer that is constantly changing. Case in point, Apple caused a lot of trouble for Adobe with the poorly performing NVIDIA drivers in the Mac OS X 10.6.4 update. For all practical purposes, using GPU acceleration in commercial software requires Adobe to have a significant automated GPU test suite to catch new driver regressions and other issues that can hamstring their applications, as manual testing alone would never catch all of the issues they see with automated testing.

The 3rd and final common theme was that GPUs aren’t a panacea and won’t solve everything. Amdahl's Law is of particular importance here, as only certain functions can be parallelized. If a route is inherently serial and cannot be done any other way, then parallelizing the rest of the code only makes sense if the serial routine is not already the biggest bottleneck; using the GPU only makes sense in the first place if the bottlenecks can easily be made to run on a GPU, and if heavy CPU/GPU communication is required as those operations are expensive.
The audience of an application also plays a big part in whether writing GPU code makes sense – most users won’t upgrade their computers for most programs, and most computers don’t have a suitable GPU for significant GPU computing. In Adobe’s case they focused on adding GPU computing first to the applications most used by professionals that were likely to upgrade their hardware for the software, and that was Premiere Pro. Premiere Elements on the other hand is a hobbyist application, and hobbyists won’t upgrade.
Finally, as for where the company is going with GPU computing, they’re in much the same boat as Cyberlink: they want to use OpenCL but they’re waiting for AMD and NVIDIA to get their drivers in order (Adobe finds new bugs almost daily). Furthermore unlike Cyberlink they find that the architecture of the GPU has a vast impact on the performance of the codepaths they use, and that when they do use OpenCL they will likely have different codepaths in some cases to better match AMD and NVIDIA’s different architectures
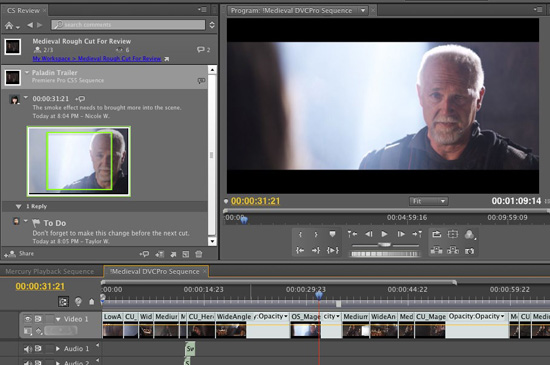
In the meantime Adobe believes that it’s quite alright to pick a vendor-specific API (i.e. CUDA) even though it limits what hardware is supported, as long as the benefits are worth it. This once more falls under the umbrella of a developer knowing their market: again going back to Premiere Pro, Premiere Pro is a product targeted at a professional market that’s likely to replace their hardware anyhow, and that market has no significant problem with the fact that Premiere Pro only supports a few different NVIDIA cards. Adobe doesn’t want to be in this situation forever, but it’s a suitable compromise for them until OpenCL is ready for widespread use.
Ultimately Adobe’s view on GPU computing is much like Cyberlink’s: there’s a place for GPU computing with consumer applications, OpenCL is the way to get there, but OpenCL isn’t ready yet. The biggest difference between the two is their perspective on whether different codepaths for different architectures are necessary: Adobe says yes, Cyberlink says no. Cyberlink’s position is more consistent with the original cross-platform goals of OpenCL, while Adobe’s position is more pragmatic in recognizing that compilers can’t completely compensate for when the code is radically different than the underlying architecture. As the consumer GPU computing market matures, it’s going to be important to keep an eye on whether one, both, or neither of these positions is right, as the ease in writing high performing GPU code is going to be a crucial factor in getting consumer GPU computing to take off for more than a handful of specialty applications.
CUDA x86
One of the things that got a lot of attention in our comments for our Day 1 article was the announcement of a CUDA-x86 compiler by STMicroelectronics’ subsidiary The Portland Group. PGI is not a company’s name we normally throw around here, as the company’s primary focus is on building compilers for High Performance Computing, particularly the CUDA Fortran compiler. A lot of people asked about PGI’s compiler and what this meant for consumer CUDA applications, so we stopped and asked them about their CUDA-x86 compiler.
The long and the short of it is that the CUDA-x86 compiler is another PGI product meant for use in the HPC market. Specifically the company is targeting national laboratories and other facilities that do HPC work with massive clusters and would like to better integrate their CPU clusters and their GPU clusters. With the CUDA-x86 compiler, these facilities can compile their CUDA HPC applications so that they can be run on their CPU clusters without any changes, allowing them to use clusters that may have otherwise gone idle since they can’t normally process applications written for CUDA. CPUs of course won’t be nearly as fast as NVIDIA GPUs for CUDA code, but in some cases this may be better than letting those clusters go idle.
What this means for consumers however is that the compiler isn’t targeted for use with consumer applications. Conceivably someone could go to PGI and purchase the CUDA-x86 compiler for use in this manner, but this isn’t something the company is currently chasing. It also goes without saying that PGI’s compilers are expensive software normally licensed on a per-node basis, making the prospects of this scenario expensive and unlikely.
NVIDIA’s VDPAU for *nix
NVIDIA’s Video Decode and Presentation API for Unix (VDPAU) was also the subject of a session at GTC. VDPAU was first introduced in 2008 in order to expose NVIDIA’s video decode hardware to *nix operating systems, as unlike Windows these OSes did not have an operating system level API like DXVA to do this. Since 2008 NVIDIA has been adding to the library, and earlier this year they added a bunch of interoperability features to the API focused on providing new ways to access the GPU as a graphical device beyond what OpenGL can do. This entails things such as being able to directly set and get bits on the GPU and enhancements specifically for desktop compositing.
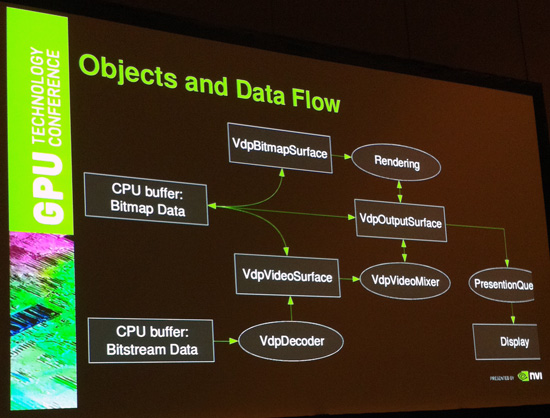
We’re not going to dwell on interoperability much, but while we were there we did ask NVIDIA about whether we’re going to see a unified video decode API for *nix any time soon. While NVIDIA has VDPAU and also has parties like S3 use it, AMD and Intel are backing the rival Video Acceleration API (VA API). Thus any *nix software that currently wants to support video decode acceleration on all GPUs needs to support the two different APIs.
The short answer according to NVIDIA is that we should not be expecting a unified API any time soon. There isn’t significant motivation on either side of the isle to come together on a single API, and with the ad-hoc nature of *nix development, there isn’t a single guiding force that can mandate anything. For the time being *nix developers looking to take advantage of video decode acceleration are going to continue to have to cover both APIs if they wish to cover the complete spectrum of GPUs.
GPU.NET: Making GPU Programming Easier
When NVIDIA and AMD started their GPU computing initiatives, both recognized that developers needed to be able to write a code at a level higher than the raw hardware. Assembly-level programming not only was mind-numbingly hard for most developers when faced with the complexity of a GPU, but allowing developers to do that meant that AMD and NVIDIA were locked in to providing low-level backwards compatibility, ala x86. Instead, both companies did a run-around on the process and focused on getting developers to use C-style languages (CUDA and Brook+, and later OpenCL) and then to have them compile these programs compile down to bytecode, which could then be further compiled down to the appropriate language by the driver itself. These bytecode languages were PTX for NVIDIA, and IL for AMD.
Furthermore by having a bytecode level, additional programming languages could in time be retrofitted to work with the GPU by writing new compilers that compiled these languages down to the right bytecode. This is what made OpenCL and DirectCompute possible, but also full languages such as Fortran. And while back in my day C++ was a perfectly reasonable high level language(ed: get off my lawn), the reality of the situation is that both NVIDIA and AMD have really only focused on low-level programming so far, leaving programmers who have come to rely on modern high level features such as inheritance and garbage collection out in the cold. As it turns out, today’s GPUs are plenty capable of running code written in a high level language, but no one has written the compiler for it until now.
While at GTC we had a chance to talk to Tidepowerd, a small company developing such a compiler in the form of GPU.NET. GPU.NET is a compiler, runtime, and library combination that can interface with the .NET languages, allowing developers to write GPU computing code in C#, F#, and even VB.NET. As lower level languages have been displaced by the .NET languages and other such languages, this allows developers who are only accustomed to these languages to write applications in their higher level language of choice, making GPU programming more accessible to the high level crowd.
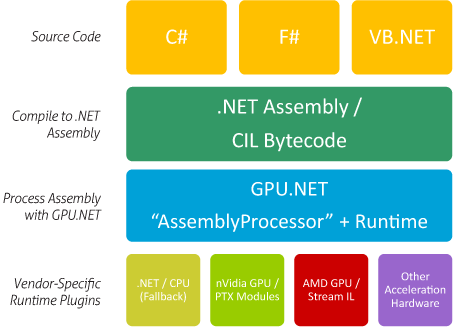
Ultimately GPU.NET is not a panacea, but it does help with accessibility. Programmers still need to be able to write parallel code – which is in and of itself hard – but they no longer need to deal with lower level constructs such as manual memory management as GPU.NET follows its .NET heritage and uses garbage collection. This also lets developers write code within Microsoft Visual Studio, and as we mentioned in our discussion on NVIDIA’s Parallel Nsight 1.5, Visual Studio support is a huge deal when it comes to reaching many programmers.
As a GPU enthusiast it’s my hope that new languages and runtimes such as GPU.NET will make GPU programming more accessible to the rank & file programmers that put together so many of today’s consumer applications, as the GPU future that NVIDIA, AMD, and Apple believe in requires more than a handful of programming wizards writing code for a few major applications. GPU.NET in particular has a hurdle to get over because it requires a runtime and runtimes are rarely looked upon favorably by users, but for the time being at least, this is what it’s going to take to write GPU compute code on the .NET languages. If not OpenCL, then hopefully the proliferation of GPU computing capable high level languages will be what’s necessary to kick start the development of GPU compute-enabled applications for consumers.







{kind=link}