ARM Announces Cortex-A72, CCI-500, and Mali-T880
by Andrei Frumusanu on February 3, 2015 5:30 PM EST- Posted in
- Smartphones
- Arm
- Mobile
- Mali
- Cortex A72
- CCI-500
- Mali T880
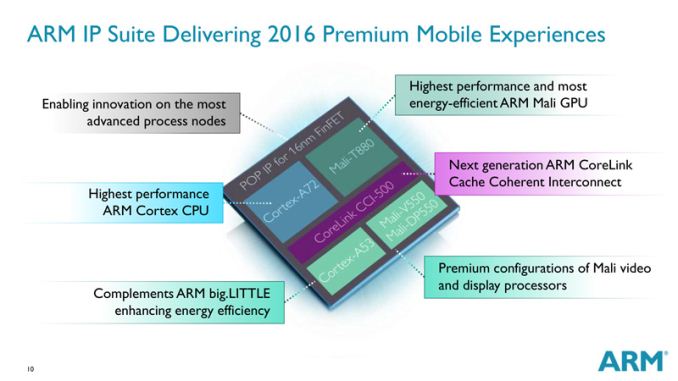
Today ARM is announcing three brand-new premium IP designs targeted at high-end mobile SoCs. We're still only starting to get widespread commercial availability of ARM's latest generation of SoCs, which includes the Cortex-A57 in big.LITTLE configuration coupled with the A53 as little cores, and the newest T760 Mali GPUs. But, while those designs are still ramping up through offerings from Samsung, Qualcomm, HiSilicon and co. this year, ARM isn't staying still and already looking forward to 2016 and beyond.
Cortex-A72 - a new high end core
At the center of today's announcements a new high-end performance core which succeeds the A57 in flagship devices. ARM was very vague about the architectural characteristics of the new design, disclosing for now only estimates of the chip's performance and power targets. ARM promises a 3.5x sustained performance increase over the A15 generation of SoCs while remaining in the same power budget. One has to note that we're talking about performance targets on TSMC's 16nm FinFET+ node versus previous nodes such as 28 and 20nm, which in itself should bring large clock and power advantages.

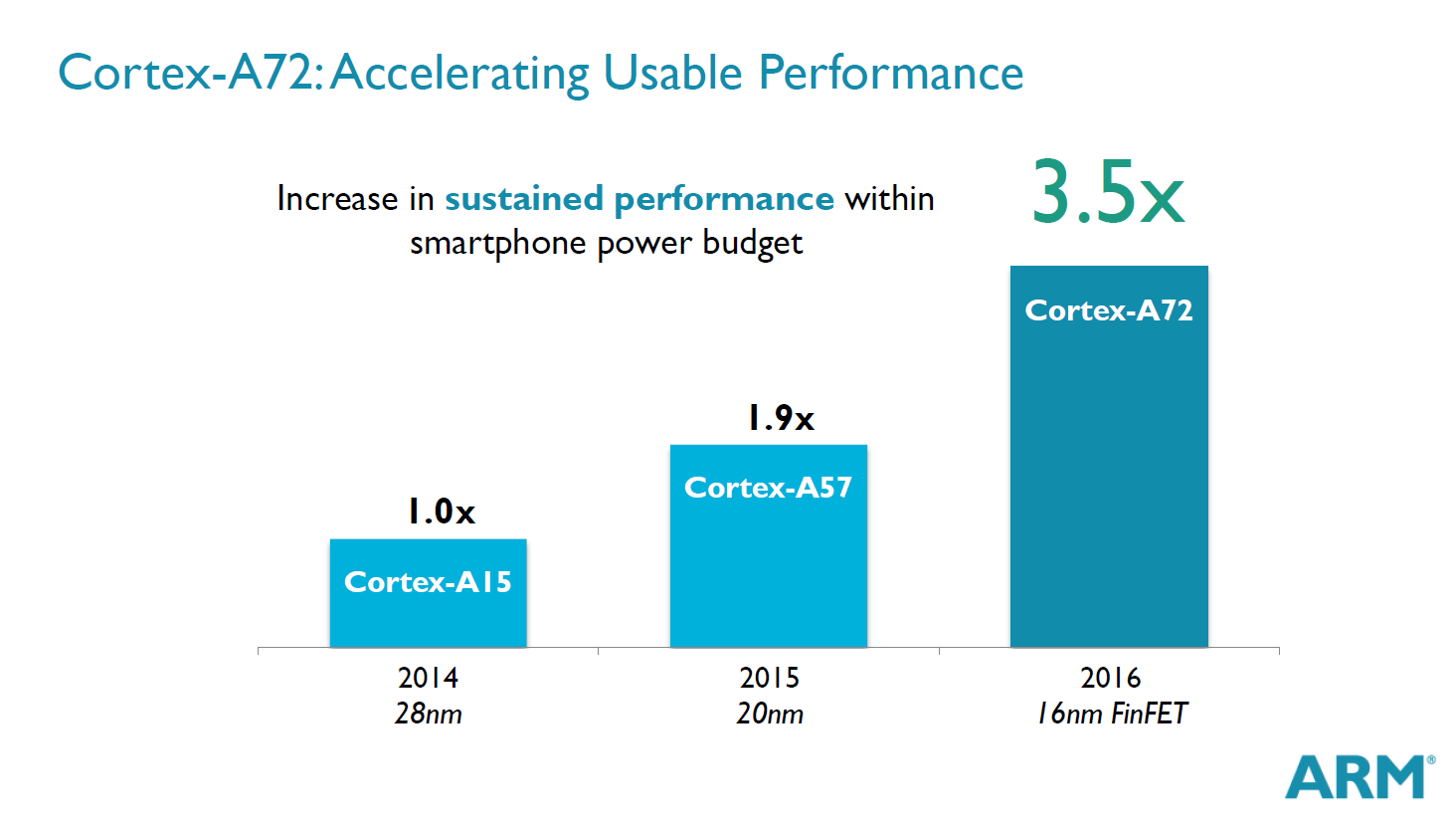
The A72 targets roughly 1.9X the sustained performance of current 20nm A57 SoCs, meaning the Exynos 5433 and the Snapdragon 810 can be taken as the base for comparisons. ARM doesn't yet mention peak performance so we may be talking about overall power efficiency gains that enable future SoCs to throttle much less. ARM will be divulging more information on the architecture of the A72 in the coming months, and we're hoping to have a better picture on the actual IPC and efficiency gains of the new flagship core by then.
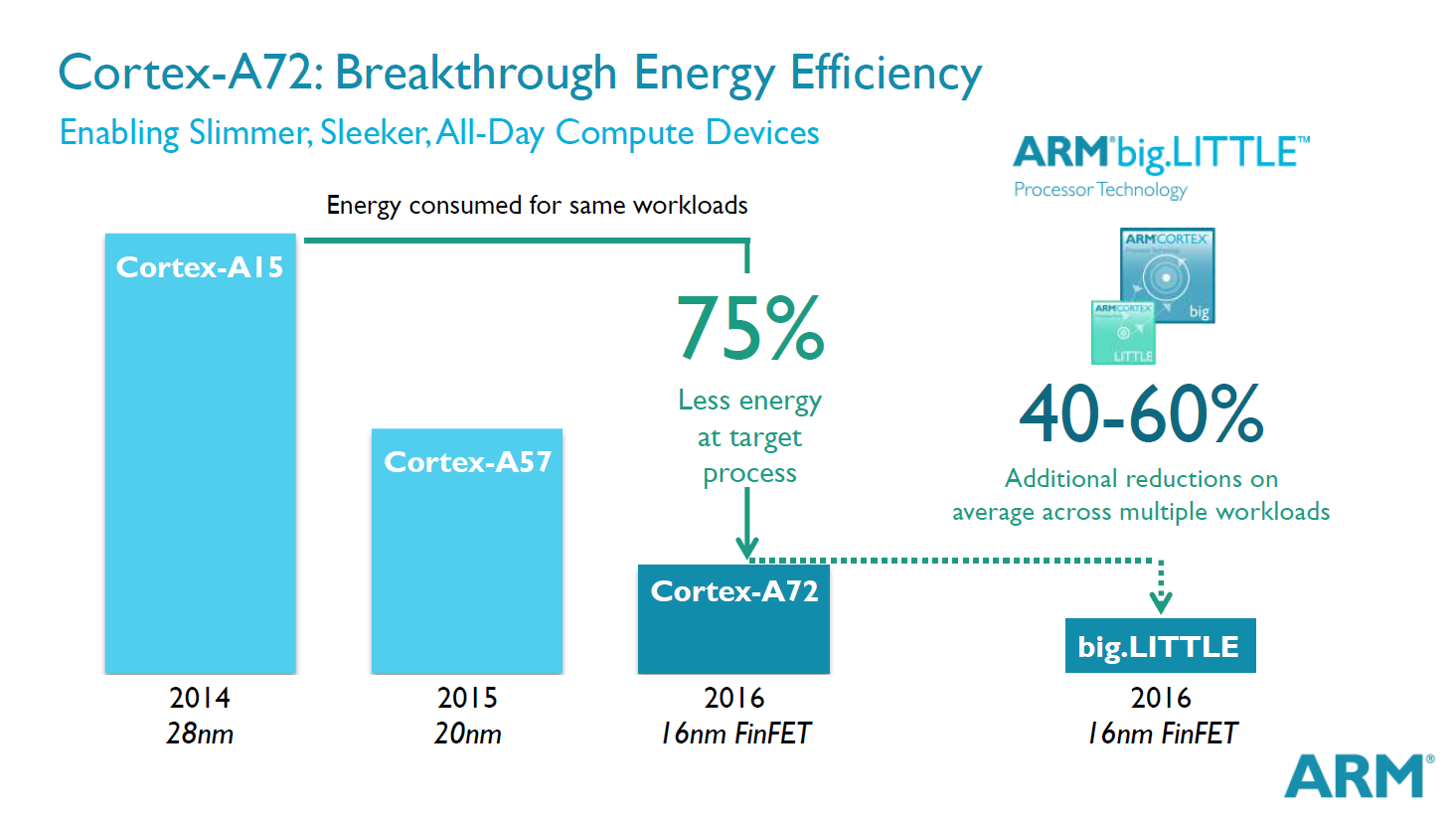
The Cortex-A72, being a "big" core, can be partnered up with the already existing A53 LITTLE core architectures. ARM has said in the past that the A53 took in-order designs to new heights, and while work on a successor is underway, it seems that for now we'll be sticking with the A53 architecture for a while longer.
HiSilicon, MediaTek and Rockchip are listed among more than then launch partners which have already licensed the Cortex-A72 processor, so expect to see a variety of vendors offering the new ARM IP in 2016.
CoreLink CCI-500 SoC interconnect
It's been over 3 years since ARM initially announced their CCI-400 (Cache Coherent Interconnect), which saw widespread usage as the corner-stone technology enabling big.LITTLE heterogeneous multiprocessing in all consumer SoCs from the Exynos 5410 to the latest Snapdragon 810. While ARM also offered high-end alternatives such as the CCN-5XX (Cache Coherent Network) range of interconnects, these were targeted more at server-applications and not meant for mobile SoCs in smartphones or tablets.

The CCI-500 is a large upgrade over the CCI-400 as it introduces a variety of new functionality over its predecessor. The largest change in functionality is the addition of a snoop filter on the interconnect itself. Until now snoop control was only possible between CPUs within a single cluster. The addition of a snoop filter on the interconnect allows for power efficiency benefits as the amount of transactions when doing cache lookups is decreased, enabling both reduced overhead on the interconnect and also higher idle residency times on the CPU cores. This reduced overhead also frees up memory bandwidth on the interconnect, and ARM claims this enables for 30% better memory performance on the CPU ports.
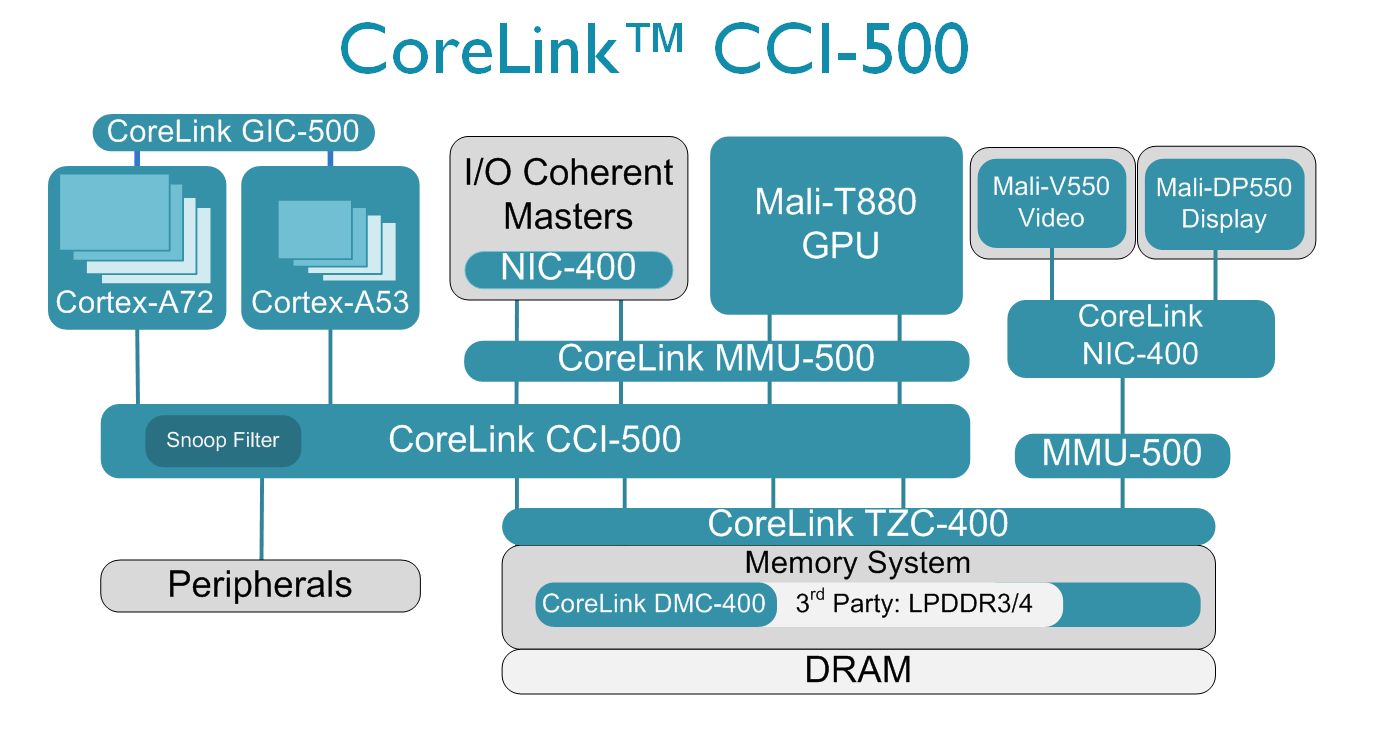
The new interconnect also doubles up on its system bandwidth: We now have twice the number of ACE (AXI Coherency Extension) ports, enabling usage of a maximum of four CPU clusters (instead of the two that are possible with the CCI-400). We'll be continuing to see the usage of only two clusters in mobile designs, but the new IP gives licensees the flexibility to deviate according to their needs.
The increased bandwidth and numbers of ports on the interconnect also opens up the possibility of quad-channel memory controllers, resulting in 128-bit memory buses. The Snapdragon 805 was the first mobile product to feature such capability, although Qualcomm used a non-cache-coherent interconnect in their design.
Mali T880 GPU
Lastly, ARM also announced a new member of the T800 series of Mali GPUs. In addition to the T820, T830 and T860 comes the T880. ARM was again light on details of what this new configuration brings, only promising a 1.8x increase performance over 2014 Mali T760 GPUs and a 40% reduction in energy consumption for the same workloads.

With today's announcements, ARM appears to be addressing its weaknesses in mobile SoCs by focusing on sustained performance and efficiency of its big core architecture. We also have the much needed upgrade in the memory/interconnect subsystem and an expansion in its GPU IP offering.
Source: ARM








49 Comments
View All Comments
Alexvrb - Thursday, February 5, 2015 - link
Even Nvidia sells a version of their K1 (and probably future) SoC loaded up with stock ARM cores. Does any mass-market hardware even use their twin-core Denver design? I haven't bothered to look after finding out that most K1s are actually just Tegra 5.A.Noid - Monday, February 9, 2015 - link
I believe that the Nexus 9 is using Denver. It's 64 bit I think.phoenix_rizzen - Wednesday, February 4, 2015 - link
2x big cores + 4x LITTLE cores makes the most sense.Phones like the Motorola Moto G have shown that 4x LITTLE cores is plenty of power for everyday usage, but isn't quite enough for power users, gaming, and heavy usage. So tack on a pair of big cores to handle those situations and you pretty much have the perfect SoC. Just need a skookum GPU to match.
I'm really looking forward to something like a Z3 Compact with a Snapdragon S808 SoC (2x Cortex-A57 + 4x Cortex-A53 CPUs with Adreno 405 GPU).
Valis - Wednesday, February 4, 2015 - link
Sadly I haven't seen one device yet being announced with the rather fine Snapdragon 808, only 615 with 5-5'5 inch screen and a bunch of high-end with 810. :-/name99 - Wednesday, February 4, 2015 - link
How does 4 little cores "make the most sense"?The problem is that phone workloads are, for the most part, unpredictable.
When you have a predictable workload (for example many server workloads) you can put bounds on acceptable latency, and you can partition your workload, as appropriate, between low and high latency cores.
But on a phone MOST of your workload is going to consist of "respond to user input, and do so as fast as possible". There is some ongoing background stuff that you can relegate to a low performance core, but it's not clear that you need an A53 for that --- Apple seems to do OK running that stuff on an ARM M3. Playing music and decoding video have predictable performance, but they are best done on dedicated HW, not using a general purpose core.
I've heard plenty of these claims about why lots of low power cores are useful, but (outside of the server space) I've never seen a single TECHNICAL explanation justifying the claim. The people supporting lotsa small cores come across as fanboys, while the people actually publishing papers and providing numbers pretty much universally agree that (again, under the constraints of the unpredictable code that runs on phones) race to complete is both lower energy AND provides a better user experience.
For example, do we have any published papers (or something similarly representative; not just vague claims) of games that deliberately pinned certain low-performance, bounded latency threads to the slower cores and thereby achieved lower energy usage than allowing those threads to time-share with other threads on the faster cores?
TeXWiller - Saturday, February 7, 2015 - link
Lets say you have a leaky process. Which would be better way to spend power while processing or waiting IO: let the big cores process the IO, or gate the more leakier cores and wake one of them only on when a small core reaches maximum sustained load so that the overhead off flushing caches and switching context is a beneficial tradeoff? Servers processors might of course have shared, more energy consuming caches for performance.It would be like a DVFS, but with the addition of "leakage switching". Given the right environment and product constraints (low energy, foundry process) it might be worth the dark silicon.
Morawka - Wednesday, February 4, 2015 - link
The perfect SoC is one that is power efficient at all workloads. The more cores you need to accomplish this task, the less efficient you are. From a cost perspective, and from a Board Surface area perspective.Power Gating is a thing you know, no need for a bunch of little cores when you have complete control over every transistor like today's soc's
Morawka - Wednesday, February 4, 2015 - link
3 words man, Time to MarketQualcomm got caught flat footed when apple released the A7, First ever 64bit ARM proccessor. Qualcomm admittedly got caught off guard. They didn't even have anything on the drawing board at that point. Their PR team downplayed 64bit advantages, and got flamed by the technical media. several PR people were fired after the whole debacle IIRC.
vayal - Wednesday, February 4, 2015 - link
At least it would make sense if it was possible to have both the BIG and little cores to operate in parallel.psychobriggsy - Wednesday, February 4, 2015 - link
It is possible to have both big and little cores running at the same time (i.e., all 8 cores running simultaneously).It's just that in typical mobile workloads, nothing actually needs the big cores until you kick off a game, or do that 1s web page render. Hence why ARM suggests two big cores as a sensible configuration.
It's just that the cores are so small, the silicon cost is very low to include more cores (especially A53s) - and this will only become more true at 16nm/14nm.
ARM Chromebooks in 2016 should feel very snappy though.