Istanbul's Improvements
The cores inside “Istanbul” are not different from those found in Shanghai. Istanbul introduces only a few improvements: HT assist, slightly higher HT speeds, APML and x8 ECC.

X8 ECC: Each DRAM chip on a DIMM provides either 4 bits or 8 bits of a 64-bit data word. Chips that provide 4 bits are called x4 (by 4), and chips that provide 8 bits are called x8 (by 8). It takes eight x8 chips or sixteen x4 chips to make a 64-bit word, so at least eight chips are located on one or both sides of a DIMM. Istanbul’s memory controller now supports error correction for both x4 and x8 DIMMs.
APML Remote Power Management Interface: APML provides an interface that allows you to monitor and control platform power consumption via P-state limits. You need to have a CPU and BMC (management processor) that support APML on the server and you need to have some type of software (OS or management software) that supports APML and allows you to monitor power and make changes to power management parameters. Both hardware and software are in development, so this won’t be available on the servers that will be launched this month. APML is interesting as it would allow you to cap power without going into the BIOS. AMD’s PowerCap Manager allows you to limit power to a certain amount by making sure the CPU’s clock never goes beyond a certain limit, effectively underclocking the CPU. This is very useful in a datacenter that is cooling or power limited. Of course, BIOS options are not that handy in a datacenter with hundreds of servers. That is where APML could make the difference.
Higher HT Speeds: The later versions of the “Shanghai” Opteron versions support HyperTransport 3.0 or HT3. HT3 allows much higher clockspeeds than the HyperTransport links that all the older Opterons have been using so far (1GHz). The clockspeed was boosted to 2.2 GHz DDR, good for 8.8 GB/s in each direction. Istanbul pushes the clock of the HyperTransport up to 2.4GHz DDR, good for 9.6 GB/s in each direction. Or as fast as the QPI links which can be found on the slower “Nehalem” Xeons. Since the new Fiorano platform is not ready, we still have to test with an older NVIDIA MCP55 platform. But that does not matter; the CPU interconnect speed is handled by the CPUs, not the board or chipset. You can clearly see in the BIOS screenshot below:
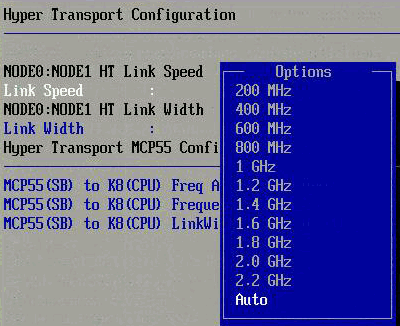
The last improvement is HT Assist. We will discuss this feature in more detail.
HT Assist: Only for the Quad-Socket
HT assist is a probe or snoop filter AMD implemented. First, let us look at a quad Shanghai system. CPU 3 needs a cacheline which CPU 1 has access to. The most recent data is however in CPU’s 2 L2-cache.
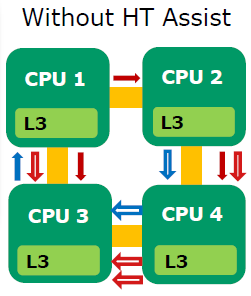
Start at CPU 3 and follow the sequence of operations:
1. CPU 3 requests information from CPU 1 (blue “data request” arrow in diagram)
2. CPU 1 broadcasts to see if another CPU has more recent data (three red “probe request” arrows in diagram)
3. CPU 3 sits idle while these probes are resolved (four red & white “probe response” arrows in diagram)
4. The requested data is sent from CPU 2 to CPU 3 (two blue and white “data response” arrows in diagram)
There are two serious problems with this broadcasting approach. Firstly, it wastes a lot of bandwidth as 10 transactions are needed to perform a relatively simple action. Secondly, those 10 transactions are adding a lot of latency to the instruction on CPU 3 that needs the piece of data (which was requested by CPU 3 to CPU 1).
The solution to is a directory-based system, that AMD calls HT Assist. HT assist reserves 1MB portion of each CPU’s L3 cache to act as a directory. This directory tracks where that CPU’s cache lines are used elsewhere in the system. In other words the L3-caches are only 5 MB large, but a lot of probe or snoop traffic is eliminated. To understand this look at the picture below:
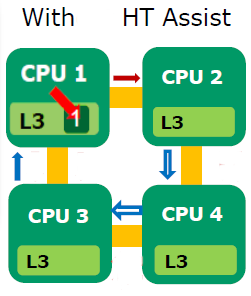
Let us see what happens. Start again with CPU 3:
1. CPU 3 requests information from CPU 1 (blue line)
2. CPU 1 checks its L3 directory cache to locate the requested data (Fat red line)
3. The read from CPU 1’s L3 directory cache indicates that CPU 2 has the most recent copy and directly probes CPU 2 (Dark red line)
4. The requested data is sent from CPU 2 to CPU 3 (blue and white lines)
Instead of 10 transactions, we have only 4 this time. A considerable reduction in latency and wasted bandwidth is the result. Probe “broadcasting” can be eliminated in 8 of 11 typical CPU-to-CPU transactions. Stream measurements show that 4-Way memory bandwidth improves 60%: 41.5GB/s with HT Assist versus 25.5GB/s without HT Assist.
But it must be clear that HT assist is only useful in a quad-socket system and of the utmost importance in octal CPU systems. In a dual system, broadcast is the same as a unicast as there is only one other CPU. HT assist also lowers the hitrate of L2-caches (5 MB instead of 6) so it should be disabled on 2P systems. If you look in the BIOS...
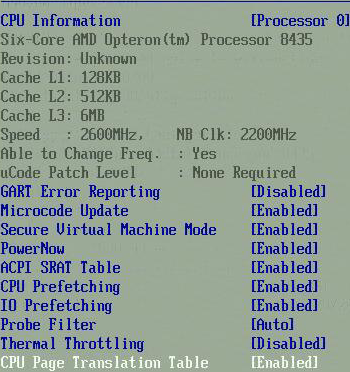
...you get 3 options next to probe filter: “auto”, “disabled” and “MP”. In automatic mode the probe filter or HT Assist will be turned off for 2P systems. You can force “HT assist” by setting “MP”, indicating there are more than 2 processors.








40 Comments
View All Comments
duploxxx - Wednesday, June 3, 2009 - link
ESX 4 should add IOMMU to the AMD istanbul platform, not sure how far this is implemented in the beta esx4 builds.Are you using the paravirtualization scsi driver in the new esx4 platform, I would expect bigegr differences between 3.5 and 4 and not just because EPT is included in esx4 together with enhanced HT.
for the rest very good thorough review.
The only thing I always miss in reviews is that although it is good to test the fastest out there, it is now where near the most deployed platform, you rather should look at the 5520-5530 against 2387 - 2431 as the mid range platform that will be deployed in a wide range of systems, this will have a much healthier performance/price/power platform then the top bin. Even the 5570 is not supported in all OEM platforms for the TDP range.
Adul - Monday, June 1, 2009 - link
I do not see oracle running on top of windows all that often. It is normally running on some *nix OS. How about running the same benchmark on say RHEL instead?InternetGeek - Monday, June 1, 2009 - link
There's actually an odd bug on Oracle's DB that makes it run faster on Windows than on Linux. Search on the internet and you'll find info about it.In the other hand, in my now 9 years in the IT industry I've only come across one Oracle DB running on HP-UX. Everything else (Sybase, MySQL, etc) runs on Windows.
LizVD - Friday, June 5, 2009 - link
Could you provide us with a link for that? I'd like to see if this "bug" corresponds with the behaviour we're seeing on our tests.Nighteye2 - Monday, June 1, 2009 - link
You give a good description of how it works and how it has so much benefit, but then you benchmark only dual-socket servers?It would be fairer to also test and compare octo-socket servers - to see the real impact of that HT assist feature.
phoenix79 - Monday, June 1, 2009 - link
Completely agreed (I was typing up a comment about this too when yours popped up)I'd love to see some 4-way VMWare scores
ltcommanderdata - Monday, June 1, 2009 - link
Yes. Nehalem is in a great position in the DP market, but isn't yet available in MP. It'd be great to see six-core Dunnington and six-core Istanbul go head to head. Conveniently their highest models have similar clock speeds at 2.66GHz and 2.6GHz respectively although Dunnington would be a lot more power hungry and although I don't remember their prices, probably more expensive too.JohanAnandtech - Tuesday, June 2, 2009 - link
Dunnington vs Istanbul coming up ... But we are going to take some time to address the shortcomings of this "deadline" article such as better power consumption readings.solori - Monday, June 1, 2009 - link
"Notice that HT-assist is a performance killer in 2P configurations: you remove two times 1 MB of L3-cache, which is a bad idea with 8 VM’s hitting your two CPUs."BIOS guidance suggests that HT Assist be disabled by default on 2P systems, and enabled only for specialized workloads. So that begs the question: Were vAPUS tests performed with or without HT Assist in the 2P configuration? It was not clear.
I assume AMD-V and RVI were enabled for ALL workloads in ESX 3.5 and 4.0 (forced for 32-bit workloads.) Is this accurate? Based on the number of ESX 3.5 installations out there, this probably should be clearly stated...
I do want to take issue with your memory sizing and estimates on vCPU loading. Let me put it this way: while Nehalem-EP has better memory bandwidth and SMT threads, Opteron has access to abundant memory. Therefore, it does not make sense - for example - to be OK with enabling SMT but then constrain the benchmark to 24GB due to a Xeon memory limitation.
I would urge you to look at 48GB configurations on Xeon and Istanbul for your comparison systems. By the way, in consolidation numbers, this makes a significant reduction in $/VM with only a minor increase in per-system CAPEX.
Another interesting issue you touched on is tuning and load balance. Great job here. These are "black magic" issues that - as you noted - can have serious effects on virtualization performance (ok, scheduling efficiency.) Knowing your platform's balance point(s) is critical to performance sensitive apps but not so critical for light-load virtualization (i.e. not performance sensitive.)
It sounds like your learning - through experimentation with vAPUS - that virtualization testing does not predict similar results from "similarly configured machines" where performance testing is concerned. In fact, the "right balance" of VM's, memory and vCPU/CPU loading for one system may be on the wrong side of the inflection point for another.
All and all, a very good article.
JohanAnandtech - Tuesday, June 2, 2009 - link
"this probably should be clearly stated... "Good suggestion. I adapted the article. RVI and EPT are always on if possible (so also 32 bit). HT-assist is of always on "Auto" (so off) unless we indicate otherwise.
"Therefore, it does not make sense - for example - to be OK with enabling SMT but then constrain the benchmark to 24GB due to a Xeon memory limitation. "
1) You must know that vApus Mark I uses too much memory for the webportals. They can run without any performance loss in 2 GB, even 1 GB. So as we move up on the number of tiles we run, it is best to reclaim the wasted memory.
2) I agree that a price comparison should include copious amount of memory (48 GB or so).
3) We don't have more than 24 GB DDR-3 available right now. It would be unfair to force the system to swap in a performance comparison.
"Opteron has access to abundant memory". What do you mean by this? Typical 2P Opterons have 64 GB, 2P Nehalems 72 GB as upper limit?
"In fact, the "right balance" of VM's, memory and vCPU/CPU loading for one system may be on the wrong side of the inflection point for another"
Great comment. Yes, that makes it even more complex to compare two systems. That is why we decided to show 2 datapoints for the 2 tile systems.
Collin, thanks for the excellent comments. It is very rewarding to notice that people take the time to dissect our hard work. Even if that means that you find wrinkles that we have to iron out. Great feedback.