Intel Xeon 7460: Six Cores to Bulldoze Opteron
by Johan De Gelas on September 23, 2008 12:00 AM EST- Posted in
- IT Computing
Our First Virtualization Benchmark: OLTP Linux on ESX 3.5 Update 2
We are excited to show you our first virtualization test performed on ESX 3.5 Update 2. This benchmarking scenario was conceived as a "not too complex" way to test hypervisor efficiency; a more complex real world test will follow later. The reason we want to make the hypervisor work hard is that this allows us to understand how much current server CPUs help the hypervisor, keeping the performance overhead of virtualization to a minimum. We chose to set up a somewhat unrealistic (at this point in time) but very hypervisor intensive scenario.
We set up between two and six virtual machines running an OLTP SysBench 0.4.8 test on MySQL 5.1.23 (INNODB Engine). Each VM runs as a guest OS on a 64-bit version of Novell's SLES 10 SP2 (SUSE Linux Enterprise Server). The advantage of using a 64-bit operating system on top of ESX 3.5 (Update 2) is that the ESX hypervisor will automatically use hardware virtualization instead of binary translation. Each virtual machine gets its own four virtual CPUs and 2GB of RAM.
To avoid I/O dominating the entire benchmark effort, each server is connected to our Promise J300S DAS via a 12Gbit/s Infiniband connection. The VMs are installed on the server disks but the databases are placed on the Promise J300S, which consists of a RAID 0 set of six 15000RPM Seagate SAS 300GB disks (one of the fastest hard disks you can get). A separate disk inside the Promise chassis is dedicated to the transactional logs; this reduces the disk "wait states" from 8% to less than 1%. Each VM gets its own private LUN.
Each server is equipped with an Adaptec RAID 5085 card. The advantage is that this card is equipped with a dual-core Intel IOP 348 1.2GHz and 512MB of DDR2, which helps us ensure the RAID controller won't be a bottleneck either.
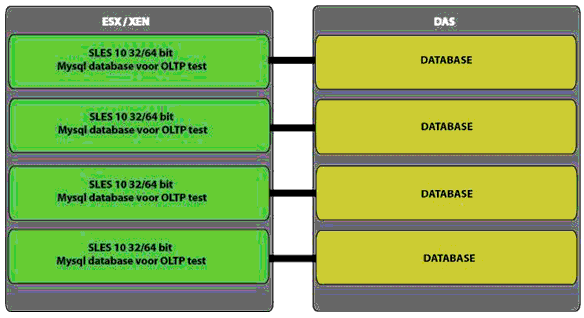
Our first virtualized benchmark scenario; the green part is the server and the yellow part is our Promise DAS enclosure.
We use Logical Volume Management (LVM). LVM makes sure that the LUNs are aligned and start at a 64KB boundary. The file system on each LUN is ext3, with the -E stride=16 option. This stride is necessary as our RAID strip size is 64KB and Linux (standard) only allows a block size of 4KB.
The MySQL version is 5.1.23 and the MySQL database is configured as follows:
max_connections=900
table_cache=1520
tmp_table_size=59M
thread_cache_size=38
#*** INNODB Specific options ***
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=10M
innodb_buffer_pool_size=950M
innodb_log_file_size=190M
innodb_thread_concurrency=10
innodb_additional_mem_pool_size=20M
Notice that we set flush_log_at_trx_commit = 1, thanks to the Battery Backup Unit on our RAID controller; our database offers full ACID behavior as appropriate for an OLTP database. We could have made the buffer pool size larger, but we also want to be able to use this benchmark scenario in VMs with less than 2GB memory. Our 1 million record database is about 258MB and indices and rows fit entirely in memory. The reason we use this approach is that we are trying to perform a CPU benchmark; also, many databases now run from memory since it is pretty cheap and abundant in current servers. Even 64GB configurations are no longer an exception.
Since we test with four CPUs per VM, an old MySQL problem reared its ugly head again. We found out that CPU usage was rather low (60-70%). The reason is a combination of the futex problems we discovered in the old versions of MySQL and the I/O scheduling of the small but very frequent log writes, which are written immediately to disk. After several weeks of testing, we discovered that using the "deadline" scheduler instead of the default CFQ (Complete Fair Queuing) I/O scheduler solved most of our CPU usage problems.
Each 64-bit SLES installation is a minimal installation without GUI (and runlevel = 3), but with gcc installed. We update the kernel to version 2.6.16.60-0.23. SysBench is compiled from source, version 0.4.8. Our local Linux gurus Philip Dubois and Tijl Deneut have scripted the benchmarking of SysBench. A master script on a Linux workstation ensures SysBench runs locally (to avoid the time drift of the virtualized servers) and makes SQL connections to each specified server while running all tests simultaneously. Each SysBench database contains 1 million records, and we start 8 to 32 threads, in steps of 8. Each test performs 50K transactions.








34 Comments
View All Comments
JarredWalton - Tuesday, September 23, 2008 - link
Heh... that's why I love the current IBM commercials."How much will this save us?"
"It will reduce our power bills by up to 40%."
"How much did we spend on power?"
"Millions."
[Cue happy music....]
What they neglect to tell you is that in order to achieve the millions of dollars in energy savings, you'll need to spend billions on hardware upgrades first. They also don't tell you whether the new servers are even faster (it's presumed, but that may not be true). Even if your AC costs double the power bills for a server, you're still only looking at something like $800 per year per server, and the server upgrades cost about 20 times as much every three to five years.
Now, if reduced power requirements on new servers mean you can fit more into your current datacenter, thus avoiding costly expansion or remodeling, that can be a real benefit. There are certainly companies that look at density as the primary consideration. There's a lot more to it than just performance, power, and price. (Support and service comes to mind....)
Loknar - Wednesday, September 24, 2008 - link
Not sure what you mean: "reduced power requirements means you can fit more into your DC". You can fill your slots regardless of power, unless I'm missing something.Anyway I agree that power requirement is the last thing we consider when populating our servers. It's good to save the environment, that's all. I don't know about other companies, but for critical servers, we buy the most performing systems, with complete disregard of the price and power consumption; because the cost of DC rental, operation (say, a technician earns more than 2000$ per year, right?) and benefits of performance will outweigh everything. So we're so happy AMD and Intel have such a fruitful competition. (And any respectable IT company is not fooled by IBM's commercial! We only buy OEM (Dell in my case) for their fast 24-hour replacement part service and worry free feeling).
JarredWalton - Wednesday, September 24, 2008 - link
I mean that if your DC has a total power and cooling capacity of say 100,000W, you can "only" fit 2000 500W servers in there, or you could fit 4000 250W servers. If you're renting rack space, this isn't a concern - it's only a concern for the owners of the data center itself.I worked at a DC for a while for a huge corporation, and I often laughed (or cried) at some of their decisions. At one point the head IT people put in 20 new servers. Why? Because they wanted to! Two of those went into production after a couple months, and the remainder sat around waiting to be used - plugged in, using power, but doing no actual processing of any data. (They had to use up the budget, naturally. Never mind that the techs working at the DC only got a 3% raise and were earning less than $18 per hour; let's go spend $500K on new servers that we don't need!)