Quad Core Intel Xeon 53xx Clovertown
by Johan De Gelas on December 27, 2006 5:00 AM EST- Posted in
- IT Computing
Quad Core Choices
True, a "dual dual core" is not really a quad core, such as AMD's upcoming quad core Barcelona chip. However, from an economical point of view it does make a lot of sense: not only is there the marketing advantage of being the "first quad core" processor, but - according to Intel - using two dual cores gives you 20% higher die yields and 12% lower manufacturing costs compared to a simulated but similar quad core design. Economical advantages aren't the only perspective, of course, and from a technical point of view there are some drawbacks.
Per core bandwidth is one of them, but frankly it receives too much attention. Only HPC applications really benefit from high bandwidth. Let us give you one example. We tested the Xeon E5345 with two and four channels of FB-DIMMs, so basically we tested with the CPU with about 17GB/s and 8.5GB/s of memory bandwidth. The result was that 3dsmax didn't care (1% difference) and that even the memory intensive benchmark SPECjbb2005 showed only an 8% difference. Intel's own benchmarks prove this further: when you increase bandwidth by 25% using a 1333 MHz FSB instead of a 1066 MHz, the TPC score is about 9% higher running on the fastest Clovertown. That performance boost would be a lot less for database applications that do not use 3TB of data. Thus, memory bandwidth for most applications - and thus IT professionals - is overrated. Memory latency on the other hand can be a critical factor.
Unfortunately for Intel, that is exactly the Achilles heel of Intel's current server platform. The numbers below are expressed in clock pulses, except the last column, where we measure in nanoseconds. All measurements were done with the latency test of CPU-z.
Anand's memory latency tests measured a 70 ns latency on a Core 2 using DDR2 667 and a desktop chipset and a 100ns latency for the same CPU with a server chipset and 667 MHz FB-DIMM. Let us add about 10 ns latency for using buffered instead of unbuffered DIMMs and using the 5000p chipset instead of Intel's desktop chipset. Based on those assumptions, a theoretical Xeon DP should be able to access 667 MHz DIMMs in about 80 ns. So using FB-DIMMs result in 25% more latency compared to DDR2, which is considerable. Intel is well aware of this as you can see from the slide below.
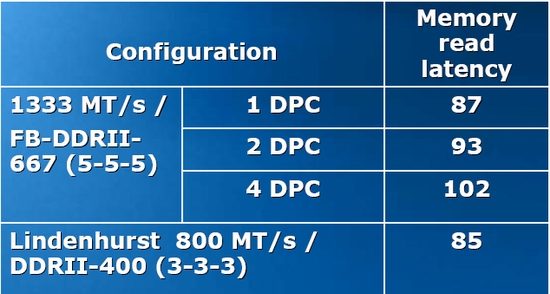
An older chipset (Lindenhurst) with slower memory (DDR2-400) is capable of offering lower latency than a sparkling new one. FB-DIMM offers a lot of advantages, such as dramatically higher bandwidth per pin and higher capacity. FB-DIMM is a huge step forward from the motherboard designer point of view. However, with 25% higher latency and 3-6 Watt more power consumption per DIMM, it remains to be seen if it is really a step forward for the server buyer.
How about bandwidth? The bandwidth tests couldn't find any real bandwidth advantage for FB-DIMM. The 533 MHz DDR2 chips delivered about 3.7GB/s (via SSE2), and about 2.7GB/s in "normal" conditions (non-SSE compiled). Compared to DDR400 on the Opteron (4.5GB/s max, 3.5GB/s), this is nothing spectacular. Of course, we tested with stream and ScienceMark, and these are single threaded numbers. Right now we don't have the right multithreaded benchmarking tools to really compare the bandwidth of complex NUMA systems such as our HP DL585 or the DIB (Dual Independent Bus) of the Xeon system.
There are much bigger technical challenges than bandwidth. Two Xeon 53xx CPUs have a total of four L2 caches, which all must remain consistent. That results in quite a bit of cache coherency traffic that has to pass over the FSB to the chipset, and from the chipset to the other independent FSB. To avoid making the four cache controllers listen (snoop) all those messages, Intel implemented a "snoop filter", a sort of cache that keeps track of the coherency state info of all cache lines mapped. The snoop filter tries to prevent unnecessary cache coherency traffic from being sent to the other Independent Bus.

The impact that cache coherency has on performance is not something only academics discuss; it is a real issue. Intel's successor of the 5000p chipset, codenamed "Seaburg", will feature a more intelligent and larger snoop filter (SF) and is expected to deliver 5% higher performance in bandwidth/FP intensive applications (measured in LS Dyna, Fluent and SpecFP). Seaburg's larger SF will be split up into four sets instead of Blackford's two, which allows it to keep track of each separate L2 cache more efficiently.
To quantify the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache, take a look at the numbers below. We have used Cache2Cache before, and you can find more info here. Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
The Xeons based on the Core architecture (E5345 and 5160) can keep cache coherency latency between the two cores to a minimum thanks to the shared L2 cache. When exchanging cache coherency information from one die from another, the Opteron does have an advantage: exchanging data goes 7 to 25% quicker. Note that the "real cache coherency latency" when running a real world workload is probably quite a bit higher for the Xeons. When the FSB has to transfer a lot of data to the memory, the FSB will be "less available" for cache coherency traffic.
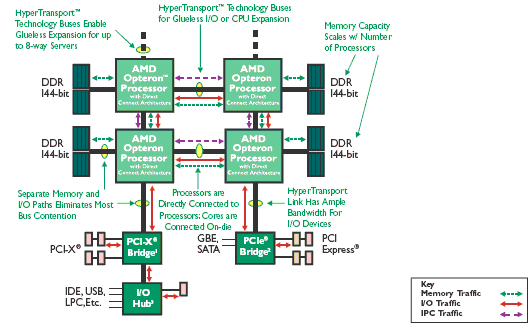
The Opteron platform can handle its cache coherency traffic via the HyperTransport links, while most of the data is transferred by the onboard memory controller to the local memory. Unless there is a lot of traffic to remote memory, the Opteron doesn't have to send the cache coherency traffic the same way as the data being processed.
So when we look at our benchmarking numbers, it is good to remember that cache coherency traffic and high latency accesses to the memory might slow our multiprocessing systems down.
True, a "dual dual core" is not really a quad core, such as AMD's upcoming quad core Barcelona chip. However, from an economical point of view it does make a lot of sense: not only is there the marketing advantage of being the "first quad core" processor, but - according to Intel - using two dual cores gives you 20% higher die yields and 12% lower manufacturing costs compared to a simulated but similar quad core design. Economical advantages aren't the only perspective, of course, and from a technical point of view there are some drawbacks.
Per core bandwidth is one of them, but frankly it receives too much attention. Only HPC applications really benefit from high bandwidth. Let us give you one example. We tested the Xeon E5345 with two and four channels of FB-DIMMs, so basically we tested with the CPU with about 17GB/s and 8.5GB/s of memory bandwidth. The result was that 3dsmax didn't care (1% difference) and that even the memory intensive benchmark SPECjbb2005 showed only an 8% difference. Intel's own benchmarks prove this further: when you increase bandwidth by 25% using a 1333 MHz FSB instead of a 1066 MHz, the TPC score is about 9% higher running on the fastest Clovertown. That performance boost would be a lot less for database applications that do not use 3TB of data. Thus, memory bandwidth for most applications - and thus IT professionals - is overrated. Memory latency on the other hand can be a critical factor.
Unfortunately for Intel, that is exactly the Achilles heel of Intel's current server platform. The numbers below are expressed in clock pulses, except the last column, where we measure in nanoseconds. All measurements were done with the latency test of CPU-z.
| CPU-Z Memory Latency | ||||||
| CPU | L1 | L2 | L3 | min mem | max mem | Absolute latency (ns) |
| Dual DC Xeon 5160 3.0 | 3 | 14 | 69 | 380 | 127 | |
| Dual DC Xeon 5060 3.73 | 4 | 30 | 200 | 504 | 135 | |
| Dual Quad Xeon E5345 2.33 | 3 | 14 | 80 | 280 | 120 | |
| Quad DC Xeon 7130M 3.2 | 4 | 29 | 109 | 245 | 624 | 195 |
| Quad Opteron 880 2.4 | 3 | 12 | 84 | 228 | 95 | |
Anand's memory latency tests measured a 70 ns latency on a Core 2 using DDR2 667 and a desktop chipset and a 100ns latency for the same CPU with a server chipset and 667 MHz FB-DIMM. Let us add about 10 ns latency for using buffered instead of unbuffered DIMMs and using the 5000p chipset instead of Intel's desktop chipset. Based on those assumptions, a theoretical Xeon DP should be able to access 667 MHz DIMMs in about 80 ns. So using FB-DIMMs result in 25% more latency compared to DDR2, which is considerable. Intel is well aware of this as you can see from the slide below.
An older chipset (Lindenhurst) with slower memory (DDR2-400) is capable of offering lower latency than a sparkling new one. FB-DIMM offers a lot of advantages, such as dramatically higher bandwidth per pin and higher capacity. FB-DIMM is a huge step forward from the motherboard designer point of view. However, with 25% higher latency and 3-6 Watt more power consumption per DIMM, it remains to be seen if it is really a step forward for the server buyer.
How about bandwidth? The bandwidth tests couldn't find any real bandwidth advantage for FB-DIMM. The 533 MHz DDR2 chips delivered about 3.7GB/s (via SSE2), and about 2.7GB/s in "normal" conditions (non-SSE compiled). Compared to DDR400 on the Opteron (4.5GB/s max, 3.5GB/s), this is nothing spectacular. Of course, we tested with stream and ScienceMark, and these are single threaded numbers. Right now we don't have the right multithreaded benchmarking tools to really compare the bandwidth of complex NUMA systems such as our HP DL585 or the DIB (Dual Independent Bus) of the Xeon system.
There are much bigger technical challenges than bandwidth. Two Xeon 53xx CPUs have a total of four L2 caches, which all must remain consistent. That results in quite a bit of cache coherency traffic that has to pass over the FSB to the chipset, and from the chipset to the other independent FSB. To avoid making the four cache controllers listen (snoop) all those messages, Intel implemented a "snoop filter", a sort of cache that keeps track of the coherency state info of all cache lines mapped. The snoop filter tries to prevent unnecessary cache coherency traffic from being sent to the other Independent Bus.
The impact that cache coherency has on performance is not something only academics discuss; it is a real issue. Intel's successor of the 5000p chipset, codenamed "Seaburg", will feature a more intelligent and larger snoop filter (SF) and is expected to deliver 5% higher performance in bandwidth/FP intensive applications (measured in LS Dyna, Fluent and SpecFP). Seaburg's larger SF will be split up into four sets instead of Blackford's two, which allows it to keep track of each separate L2 cache more efficiently.
To quantify the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache, take a look at the numbers below. We have used Cache2Cache before, and you can find more info here. Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
| Cache2Cache Latency | |||||
| Cache coherency ping-pong (ns) | Xeon E5345 | Xeon DP 5160 | Xeon DP 5060 | Xeon 7130 | Opteron 880 |
| Same die, same package | 59 | 53 | 201 | 111 | 134 |
| Different die, same package | 154 | N/A | N/A | N/A | |
| Different die, different socket | 225 | 237 | 265 | 348 | 169-188 |
The Xeons based on the Core architecture (E5345 and 5160) can keep cache coherency latency between the two cores to a minimum thanks to the shared L2 cache. When exchanging cache coherency information from one die from another, the Opteron does have an advantage: exchanging data goes 7 to 25% quicker. Note that the "real cache coherency latency" when running a real world workload is probably quite a bit higher for the Xeons. When the FSB has to transfer a lot of data to the memory, the FSB will be "less available" for cache coherency traffic.
The Opteron platform can handle its cache coherency traffic via the HyperTransport links, while most of the data is transferred by the onboard memory controller to the local memory. Unless there is a lot of traffic to remote memory, the Opteron doesn't have to send the cache coherency traffic the same way as the data being processed.
So when we look at our benchmarking numbers, it is good to remember that cache coherency traffic and high latency accesses to the memory might slow our multiprocessing systems down.








15 Comments
View All Comments
zsdersw - Friday, December 29, 2006 - link
Smithfield/Paxville is a MCM chip (two pieces of silicon in one package), as well.
Khato - Wednesday, December 27, 2006 - link
Agreed on it being quite the good review, save for the lack of power consumption numbers/analysis. Form factor and power consumption can be just as important as the performance when the application can be spread across multiple machines, now can't it? At the very least, it would be nice to link to the power consumption numbers for the opteron platform in the first review it showed up in (which puts the dual clovertown at 365W load, while the quad 880 is supposedly 657W load.)rowcroft - Wednesday, December 27, 2006 - link
Loved the article, great job.I'm in the process of purchasing two dual quad core servers for VMWare use. Looking at the cost to performance analysis, it would be worth mentioning that many of the high end applications are licensed on a per socket basis. This alone is saving us $20,000 on our VMWare license and making it a compelling solution.
I would love to see more of this type of article as well- very interesting and not something you can easily find elsewhere on the net. (Tom's hardware reviewed the chip running XP Pro!)
duploxxx - Friday, December 29, 2006 - link
If you think that reading this review will help you to decide what to buy as VMWARE base you are going the wrong way! Yes these small tests are in favor for the new MCW architecture as we saw before and since haevy workload seems hard to test for some sites like anand! keep in mind that VMWARE is heavy workload, you combine the cpu and ram to whatever you want, guess what the fsb can't be combined like you wish!thinking that a 2x quad will outperform the 4p opteron is a big laugh! the fsb will kill youre whole ESX instantly from 4+ os on your system with normal load.
the money you save is indeed for sure, the power you loose is an other thing!
friendly info from a certified esx 3.0 beta tester :)
Viditor - Wednesday, December 27, 2006 - link
Probably one of your most thorough and well-rounded articles Johan...many thanks!It was nice to see you working with large (16GB) memory.
If you do get a Socket F system, will you be updating the article?