Supermicro Ultra SYS-120U-TNR Review: Testing Dual 10nm Ice Lake Xeon in 1U
by Dr. Ian Cutress on July 22, 2021 9:00 AM ESTSystem Results and Benchmarks
When it comes down to system tests, the most obvious case in point is power consumption. Running through our benchmark tests and the IPMI does a good job of monitoring the power consumption every few minutes. We managed to see a 747 Watt peak listed, however the graph to run a few quick last photos for this reviews is showing something north of 750W.
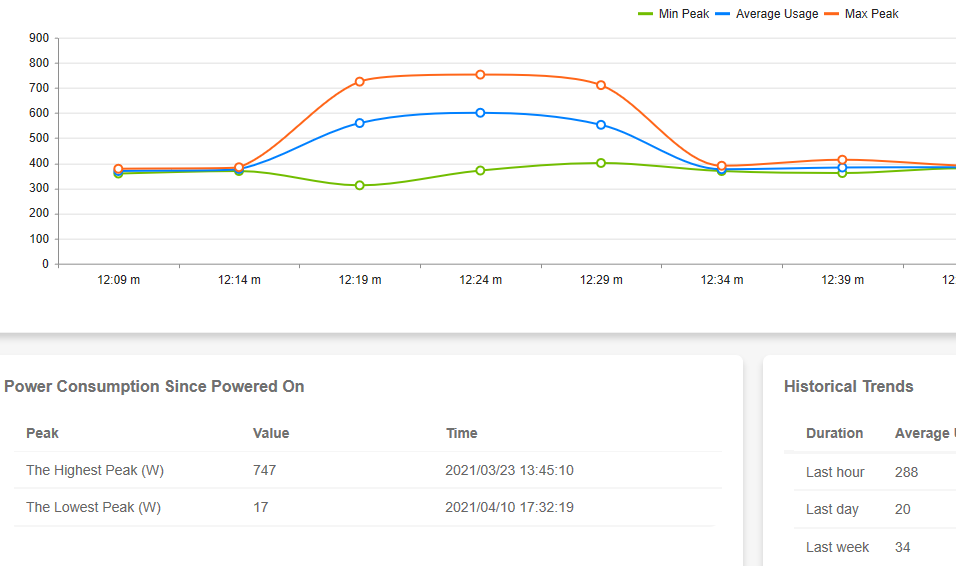
750W for a fully loaded dual 28C 2x205W system sounds quite high. This system has a peak of 1200W on the power supply, so that leaves 500W for an AI accelerator and anything additional. This means a good GPU and a dozen high power NVMe drives is about your limit. Luckily that's all you can fit into the system. Users who need 270 W processors in this system might have to cut back on some of the extras.
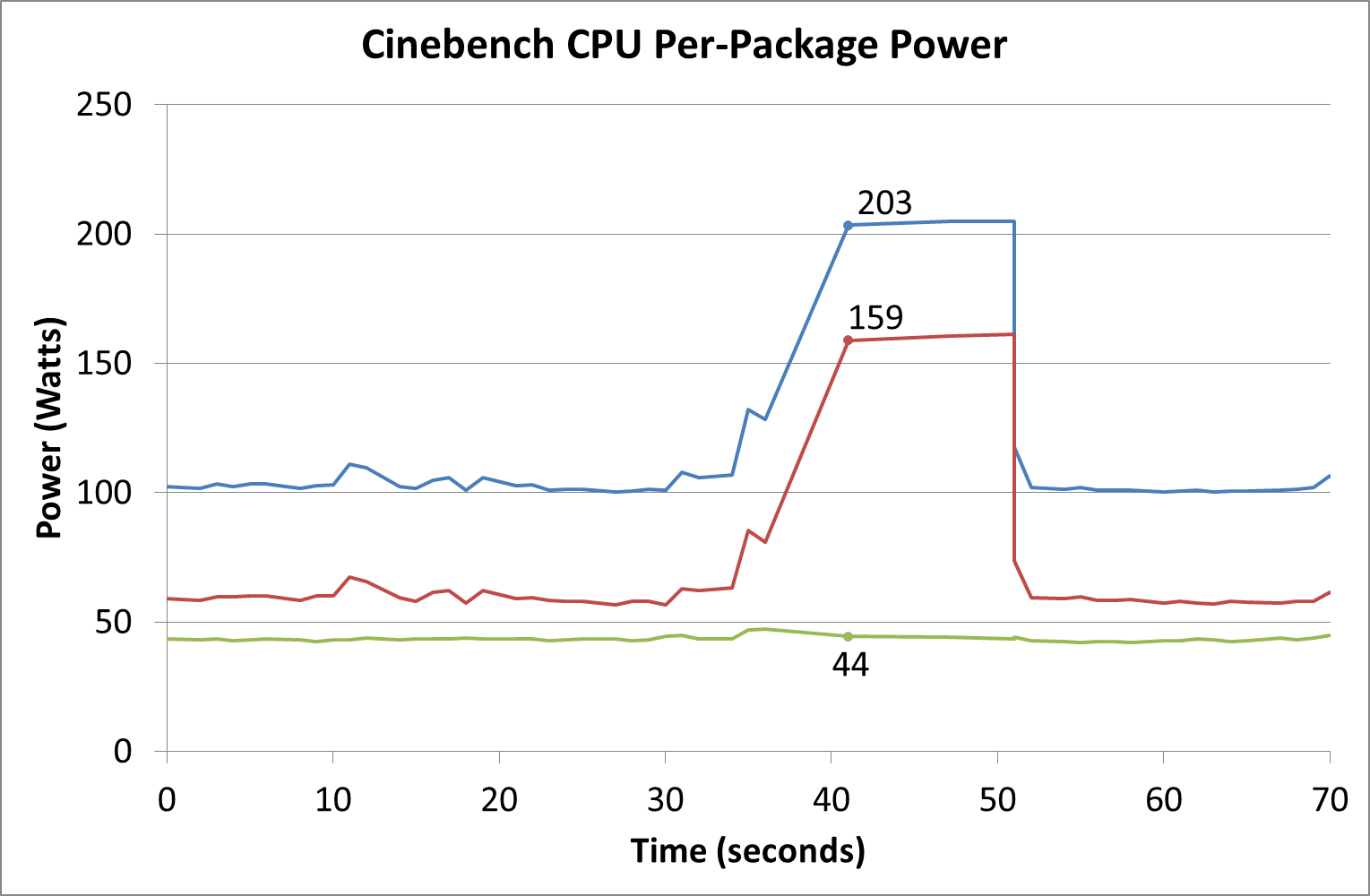
One of the elements in which to test this system at full power, and if we look at the processor power consumption we get about 205 W per processor (which is the rated TDP) during turbo.

Out of this power, it would appear that the idle power is around 100 W, which is split between cores/DRAM (we assume IO is under DRAM?). When loaded, extra budget goes into the processors. We see the same thing on CineBench, except there seems to be less stress on the DRAM/IO in this test.
Benchmarks
While we don't have a series of server specific tests, we are able to probe the capability of the system as delivered through mix of our enterprise and workstation testing. LLVM compile and SPEC are Linux based, while the rest are Windows, based on personal familiarity and also our back catalog of comparison data. It is worth noting that some software has difficulty scaling beyond 64 threads in Windows due to thread groups - this is down to the way the software is compiled and run. All the tests here were all able to dismiss this limitation except LinX LINPACK, which has a 64 thread limit (and is limited to Intel).
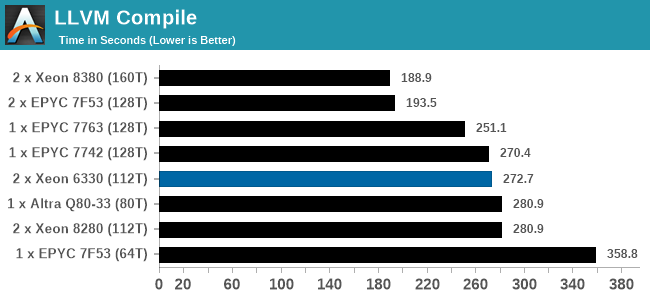
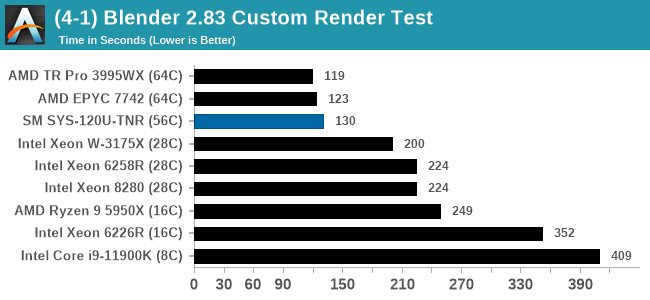
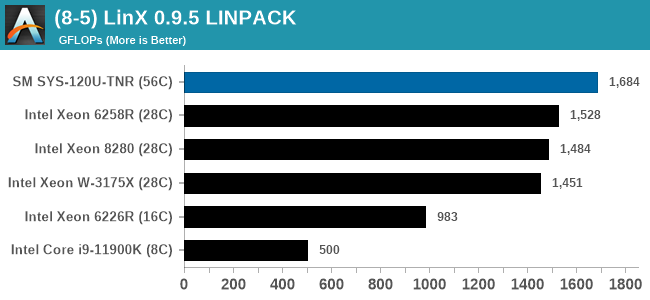
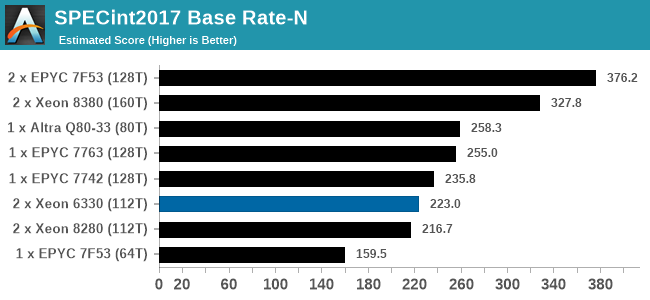
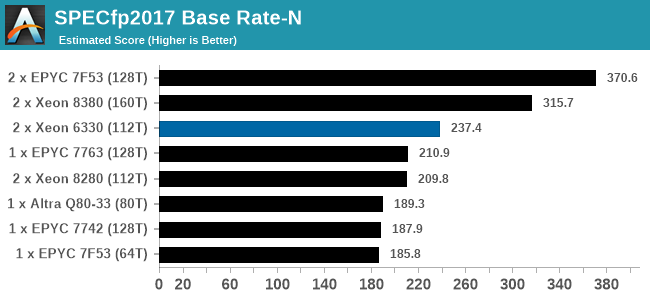
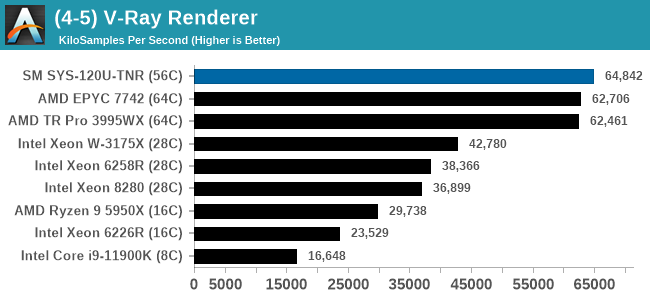
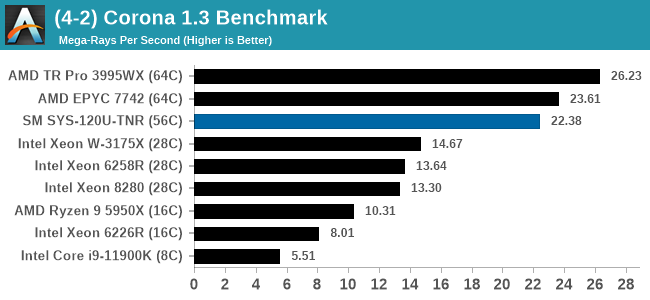
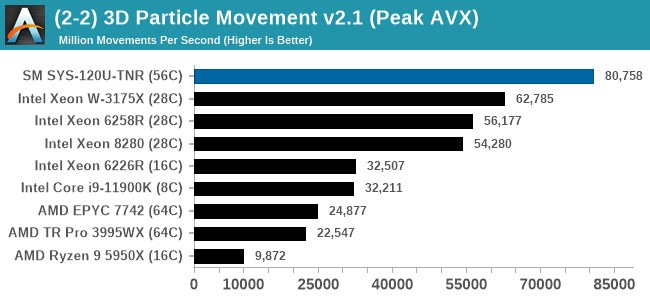
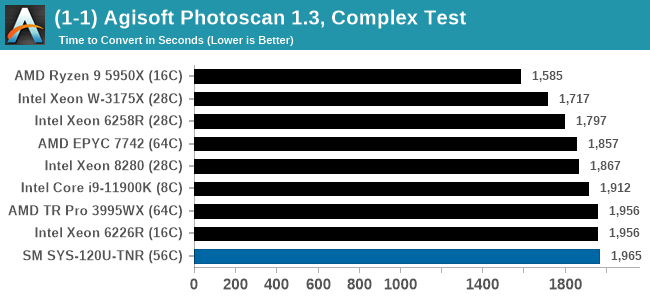
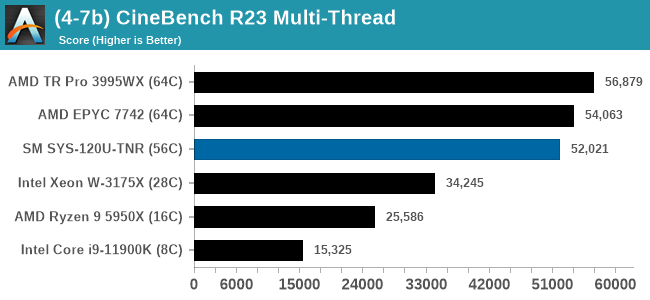
In almost all cases, the dual socket 28C SYS-120U-TNR sits behind the single socket 64C option from AMD. For the tests against dual 8280 or dual 6258R, we can see a generational uplift, however there is still a struggle against a AMD's previous generation top tier processor. That said, AMD's processor costs $6950, whereas two of these 6330s is around $3800. There is always a balance between price, total cost of ownership, and benefits versus the complexities of a dual socket system against a single socket system. The benchmarks where the SYS-120U-TNR did the best were our AVX tests, such as 3DPM and y-cruncher, where these processors could use AVX-512. As stated by Intel's Lisa Spelman in our recent interview, "70% of those deal wins, the reason listed by our salesforce for that win was AVX-512; optimization is real".








53 Comments
View All Comments
mode_13h - Friday, July 23, 2021 - link
> It's a real-world workloadExcept it's not. It started out that way, but then he gave it to Intel to optimize the AVX-512 path. So, the AVX-512 is optimized by "a world expert, according to Jim Keller" (to paraphrase Ian). And yet, the AVX-512 results are put up against the AVX2 results, on AMD CPUs, as if they're both optimized to the same degree and that just happens to be the *actual* difference in performance.
As an excuse for this, Ian points out that he gave AMD the same opportunity, but they haven't taken him up on it. Well, that still doesn't make it a fair representation of AVX2 vs. AVX-512 performance.
> I'm not sure the point should be to microoptimize it to the ends of the world,
> or it wouldn't be a realistic workload any longer.
A lot of workloads are heavily-optimized. This includes kernels in HPC programs, many games, and the most popular video compression engines. Probably a lot of stuff in SPEC Bench has been optimized a high degree. And let's not even start on AI frameworks.
All I want to do is see if people can close the gap between AVX2 and AVX-512 somewhat, or at least explain why it's as big as it is. Maybe there's some magic AVX-512 instructions that have no equivalent in AVX2, which turn out to be huge wins. It would at least be nice to know.
Plus, there's my point about optimizing it for ARM NEON and SVE, so it could be used in a somewhat apples-to-apples comparison with ARM processors.
GeoffreyA - Friday, July 23, 2021 - link
I agree it's unfair. On the "non-AVX" test, the Ryzens go to the top. On one hand, the test shows how much faster an AVX512 processor can be. On the other hand, it's unfair that some are running the AVX2 path and some the AVX512, and the results are put together. (Reminiscent of the Athlon XP's SSE not being used in some benchmarks.)Others, I don't know, but in a thing like HEVC encoding, the gains aren't all that much for these instructions. It leads me to feel the 3DPM test is gaining disproportionately from AVX512, in a narrow sort of way, and that's being magnified. The result shows, "Look at how fast these AVX512 CPUs are, leaving their AMD counterparts in the dust."
https://networkbuilders.intel.com/docs/acceleratin...
https://software.intel.com/content/www/us/en/devel...
mode_13h - Saturday, July 24, 2021 - link
> it's unfair that some are running the AVX2 path and some the AVX512,> and the results are put together.
That's a reasonable position, but I'm not even going that far. I'm okay with putting up AVX2 against AVX-512, but I think they need to be optimized somewhat comparably. That way, the difference you see only shows the true difference in hardware capability, and not also the (unknown) difference in the level of code optimization.
> "Look at how fast these AVX512 CPUs are, leaving their AMD counterparts in the dust."
It does have a few specialized instructions that have no AVX2 counterpart. And if you're doing something they were specifically designed to accelerate, then you can get a legit order of magnitude speedup. And it's not impossible 3DPM hit one of those cases. But, in order to know, Ian really needs to disclose the code.
GeoffreyA - Saturday, July 24, 2021 - link
"it's not impossible 3DPM hit one of those cases"Possible, even likely. And if so, it's a bit of an unbalanced picture. It will be interesting to see what happens when AMD adds support.
mode_13h - Sunday, July 25, 2021 - link
> Possible, even likely.We don't know, so don't presume. There are some obvious things you can get wrong that sabotage performance. Cache thrashing, pointer aliasing, and false sharing, just to name a few. Probably a lot of the speedup, in the AVX-512 case, was fixing just such things.
Spunjji - Monday, July 26, 2021 - link
@GeoffreyA - I would argue that it wouldn't necessarily be unbalanced if the benchmark benefits particularly heavily from AVX-512, simply because there are going to be workloads like that out there, and the people who have them are probably going to be aware of that to some extent.With comparable optimisation between the AVX2 and AVX-512 code paths, it could still be a helpful example of a best-case for the feature, for those few people for whom it's going to work out like that.
For everyone else, we could definitely do with more generalised real-world examples (like x264) where the AVX-512 part of the workload isn't necessarily dominant.
GeoffreyA - Wednesday, July 28, 2021 - link
That's a good way of looking at it, Spunjji. You're right. Hopefully we can those balanced, real-world examples in addition.GeoffreyA - Saturday, July 24, 2021 - link
And for a best AVX2 vs. best AVX512, I think we probably need some bigger test, something like encoding I would think. I could be wrong, but remember reading that x264 had AVX512 support. I doubt whether it's been optimised to the fullest, though. And most of the critical work on x264 was done a long time ago.GeoffreyA - Sunday, July 25, 2021 - link
My mistake. x265.mode_13h - Sunday, July 25, 2021 - link
Yeah, some of the rendering and encoding benchmarks use it.