NVIDIA Unveils Grace: A High-Performance Arm Server CPU For Use In Big AI Systems
by Ryan Smith on April 12, 2021 12:20 PM EST
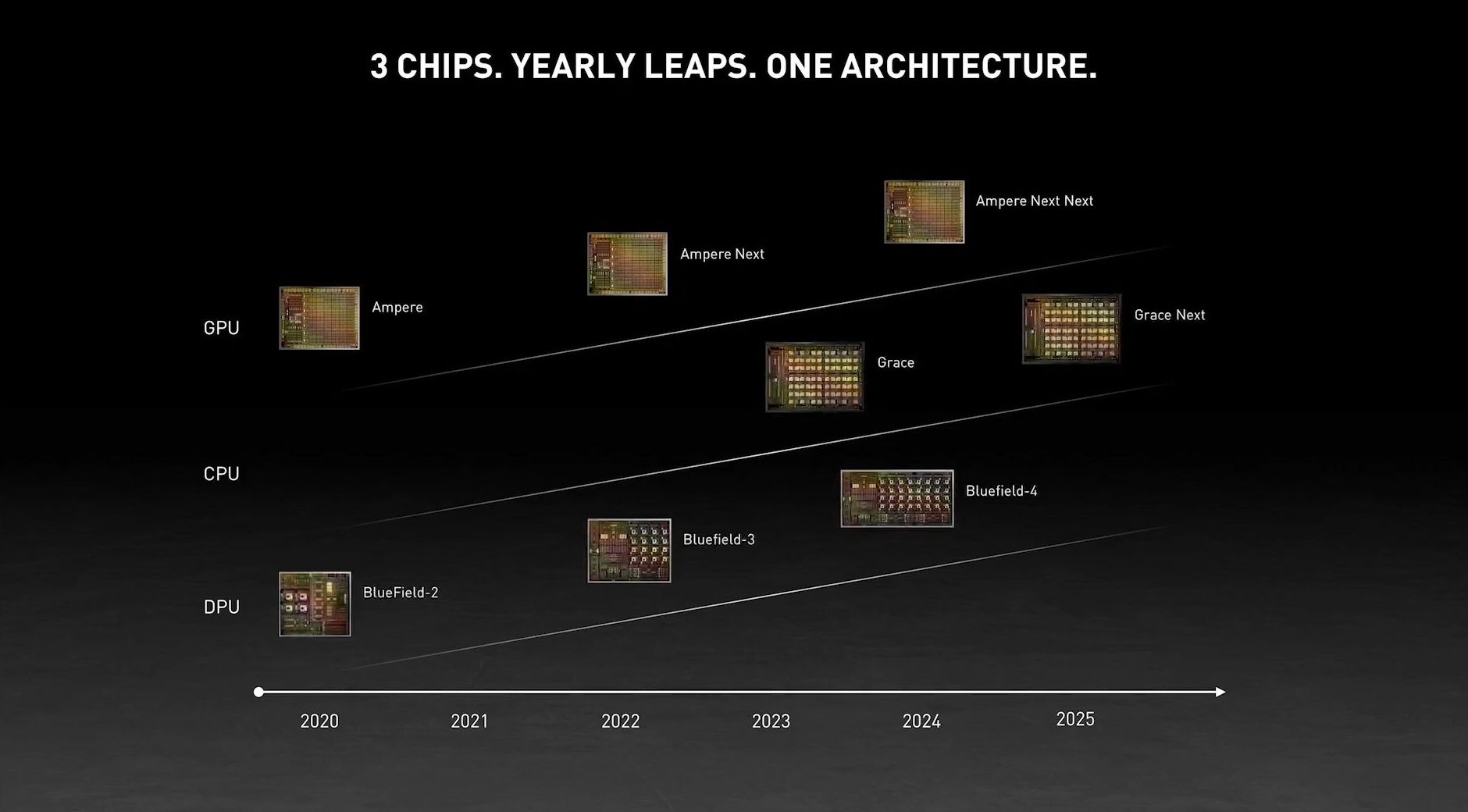
Kicking off another busy Spring GPU Technology Conference for NVIDIA, this morning the graphics and accelerator designer is announcing that they are going to once again design their own Arm-based CPU/SoC. Dubbed Grace – after Grace Hopper, the computer programming pioneer and US Navy rear admiral – the CPU is NVIDIA’s latest stab at more fully vertically integrating their hardware stack by being able to offer a high-performance CPU alongside their regular GPU wares. According to NVIDIA, the chip is being designed specifically for large-scale neural network workloads, and is expected to become available in NVIDIA products in 2023.
With two years to go until the chip is ready, NVIDIA is playing things relatively coy at this time. The company is offering only limited details for the chip – it will be based on a future iteration of Arm’s Neoverse cores, for example – as today’s announcement is a bit more focused on NVIDIA’s future workflow model than it is speeds and feeds. If nothing else, the company is making it clear early on that, at least for now, Grace is an internal product for NVIDIA, to be offered as part of their larger server offerings. The company isn’t directly gunning for the Intel Xeon or AMD EPYC server market, but instead they are building their own chip to complement their GPU offerings, creating a specialized chip that can directly connect to their GPUs and help handle enormous, trillion parameter AI models.
| NVIDIA SoC Specification Comparison | |||||
| Grace | Xavier | Parker (Tegra X2) |
|||
| CPU Cores | ? | 8 | 2 | ||
| CPU Architecture | Next-Gen Arm Neoverse (Arm v9?) |
Carmel (Custom Arm v8.2) |
Denver 2 (Custom Arm v8) |
||
| Memory Bandwidth | >500GB/sec LPDDR5X (ECC) |
137GB/sec LPDDR4X |
60GB/sec LPDDR4 |
||
| GPU-to-CPU Interface | >900GB/sec NVLink 4 |
PCIe 3 | PCIe 3 | ||
| CPU-to-CPU Interface | >600GB/sec NVLink 4 |
N/A | N/A | ||
| Manufacturing Process | ? | TSMC 12nm | TSMC 16nm | ||
| Release Year | 2023 | 2018 | 2016 | ||
More broadly speaking, Grace is designed to fill the CPU-sized hole in NVIDIA’s AI server offerings. The company’s GPUs are incredibly well-suited for certain classes of deep learning workloads, but not all workloads are purely GPU-bound, if only because a CPU is needed to keep the GPUs fed. NVIDIA’s current server offerings, in turn, typically rely on AMD’s EPYC processors, which are very fast for general compute purposes, but lack the kind of high-speed I/O and deep learning optimizations that NVIDIA is looking for. In particular, NVIDIA is currently bottlenecked by the use of PCI Express for CPU-GPU connectivity; their GPUs can talk quickly amongst themselves via NVLink, but not back to the host CPU or system RAM.

The solution to the problem, as was the case even before Grace, is to use NVLink for CPU-GPU communications. Previously NVIDIA has worked with the OpenPOWER foundation to get NVLink into POWER9 for exactly this reason, however that relationship is seemingly on its way out, both as POWER’s popularity wanes and POWER10 is skipping NVLink. Instead, NVIDIA is going their own way by building an Arm server CPU with the necessary NVLink functionality.
The end result, according to NVIDIA, will be a high-performance and high-bandwidth CPU that is designed to work in tandem with a future generation of NVIDIA server GPUs. With NVIDIA talking about pairing each NVIDIA GPU with a Grace CPU on a single board – similar to today’s mezzanine cards – not only does CPU performance and system memory scale up with the number of GPUs, but in a roundabout way, Grace will serve as a co-processor of sorts to NVIDIA’s GPUs. This, if nothing else, is a very NVIDIA solution to the problem, not only improving their performance, but giving them a counter should the more traditionally integrated AMD or Intel try some sort of similar CPU+GPU fusion play.
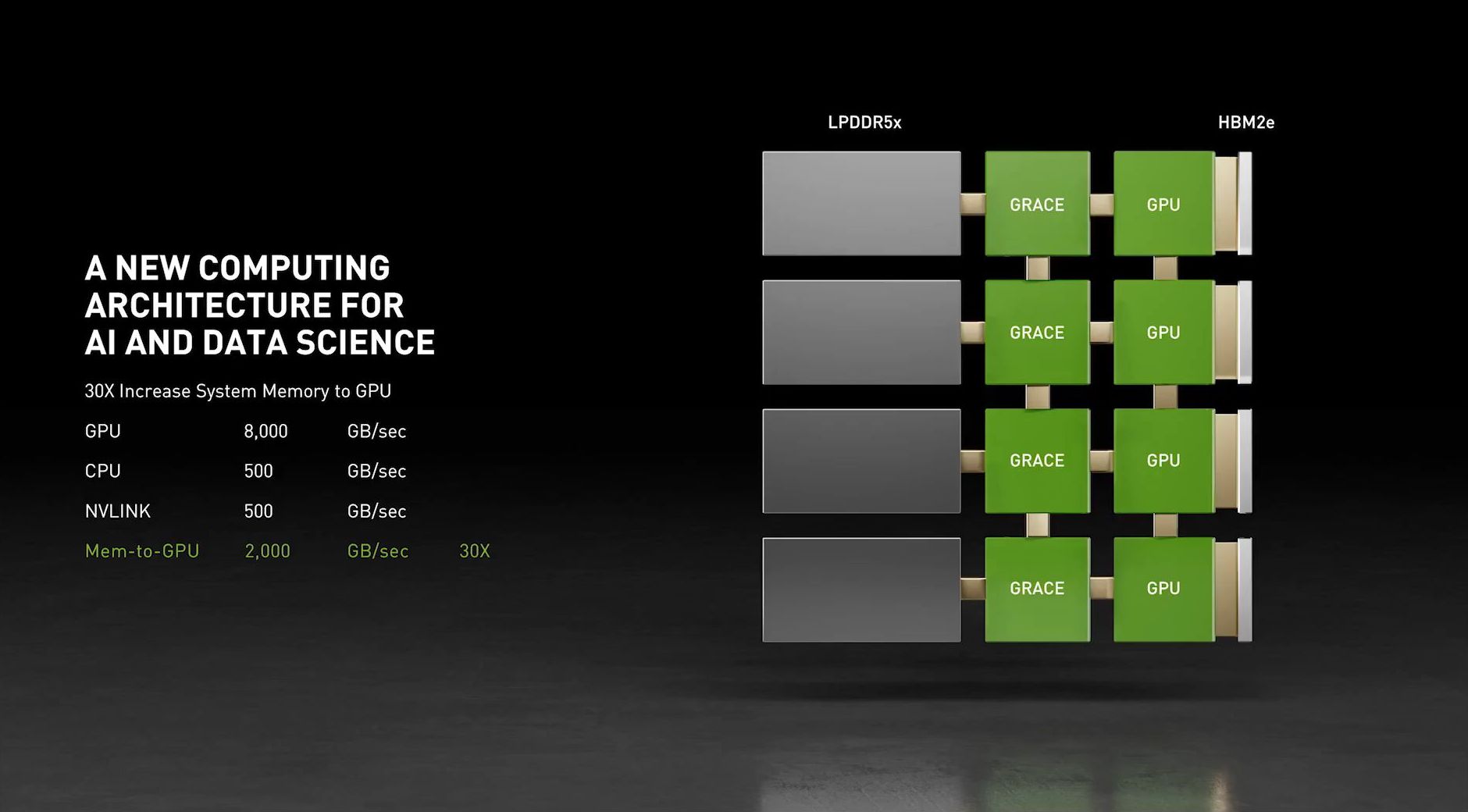
By 2023 NVIDIA will be up to NVLink 4, which will offer at least 900GB/sec of cummulative (up + down) bandwidth between the SoC and GPU, and over 600GB/sec cummulative between Grace SoCs. Critically, this is greater than the memory bandwidth of the SoC, which means that NVIDIA’s GPUs will have a cache coherent link to the CPU that can access the system memory at full bandwidth, and also allowing the entire system to have a single shared memory address space. NVIDIA describes this as balancing the amount of bandwidth available in a system, and they’re not wrong, but there’s more to it. Having an on-package CPU is a major means towards increasing the amount of memory NVIDIA’s GPUs can effectively access and use, as memory capacity continues to be the primary constraining factors for large neural networks – you can only efficiently run a network as big as your local memory pool.
| CPU & GPU Interconnect Bandwidth | |||||
| Grace | EPYC 2 + A100 | EPYC 1 + V100 | |||
| GPU-to-CPU Interface (Cummulative, Both Directions) |
>900GB/sec NVLink 4 |
~64GB/sec PCIe 4 x16 |
~32GB/sec PCIe 3 x16 |
||
| CPU-to-CPU Interface (Cummulative, Both Directions) |
>600GB/sec NVLink 4 |
304GB/sec Infinity Fabric 2 |
152GB/sec Infinity Fabric |
||
And this memory-focused strategy is reflected in the memory pool design of Grace, as well. Since NVIDIA is putting the CPU on a shared package with the GPU, they’re going to put the RAM down right next to it. Grace-equipped GPU modules will include a to-be-determined amount of LPDDR5x memory, with NVIDIA targeting at least 500GB/sec of memory bandwidth. Besides being what’s likely to be the highest-bandwidth non-graphics memory option in 2023, NVIDIA is touting the use of LPDDR5x as a gain for energy efficiency, owing to the technology’s mobile-focused roots and very short trace lengths. And, since this is a server part, Grace’s memory will be ECC-enabled, as well.
As for CPU performance, this is actually the part where NVIDIA has said the least. The company will be using a future generation of Arm’s Neoverse CPU cores, where the initial N1 design has already been turning heads. But other than that, all the company is saying is that the cores should break 300 points on the SPECrate2017_int_base throughput benchmark, which would be comparable to some of AMD’s second-generation 64 core EPYC CPUs. The company also isn’t saying much about how the CPUs are configured or what optimizations are being added specifically for neural network processing. But since Grace is meant to support NVIDIA’s GPUs, I would expect it to be stronger where GPUs in general are weaker.
Otherwise, as mentioned earlier, NVIDIA big vision goal for Grace is significantly cutting down the time required for the largest neural networking models. NVIDIA is gunning for 10x higher performance on 1 trillion parameter models, and their performance projections for a 64 module Grace+A100 system (with theoretical NVLink 4 support) would be to bring down training such a model from a month to three days. Or alternatively, being able to do real-time inference on a 500 billion parameter model on an 8 module system.
Overall, this is NVIDIA’s second real stab at the data center CPU market – and the first that is likely to succeed. NVIDIA’s Project Denver, which was originally announced just over a decade ago, never really panned out as NVIDIA expected. The family of custom Arm cores was never good enough, and never made it out of NVIDIA’s mobile SoCs. Grace, in contrast, is a much safer project for NVIDIA; they’re merely licensing Arm cores rather than building their own, and those cores will be in use by numerous other parties, as well. So NVIDIA’s risk is reduced to largely getting the I/O and memory plumbing right, as well as keeping the final design energy efficient.
If all goes according to plan, expect to see Grace in 2023. NVIDIA is already confirming that Grace modules will be available for use in HGX carrier boards, and by extension DGX and all the other systems that use those boards. So while we haven’t seen the full extent of NVIDIA’s Grace plans, it’s clear that they are planning to make it a core part of future server offerings.
First Two Supercomputer Customers: CSCS and LANL
And even though Grace isn’t shipping until 2023, NVIDIA has already lined up their first customers for the hardware – and they’re supercomputer customers, no less. Both the Swiss National Supercomputing Centre (CSCS) and Los Alamos National Laboratory are announcing today that they’ll be ordering supercomputers based on Grace. Both systems will be built by HPE’s Cray group, and are set to come online in 2023.
CSCS’s system, dubbed Alps, will be replacing their current Piz Daint system, a Xeon plus NVIDIA P100 cluster. According to the two companies, Alps will offer 20 ExaFLOPS of AI performance, which is presumably a combination of CPU, CUDA core, and tensor core throughput. When it’s launched, Alps should be the fastest AI-focused supercomputer in the world.

An artist's rendition of the expected Alps system
Interestingly, however, CSCS’s ambitions for the system go beyond just machine learning workloads. The institute says that they’ll be using Alps as a general purpose system, working on more traditional HPC-type tasks as well as AI-focused tasks. This includes CSCS’s traditional research into weather and the climate, which the pre-AI Piz Daint is already used for as well.
As previously mentioned, Alps will be built by HPE, who will be basing on their previously-announced Cray EX architecture. This would make NVIDIA’s Grace the second CPU option for Cray EX, along with AMD’s EPYC processors.
Meanwhile Los Alamos’ system is being developed as part of an ongoing collaboration between the lab and NVIDIA, with LANL set to be the first US-based customer to receive a Grace system. LANL is not discussing the expected performance of their system beyond the fact that it’s expected to be “leadership-class,” though the lab is planning on using it for 3D simulations, taking advantage of the largest data set sizes afforded by Grace. The LANL system is set to be delivered in early 2023.








119 Comments
View All Comments
mode_13h - Monday, April 12, 2021 - link
If you're looking at the roadmap slide, that's "Grace Next" -- its successor.From the article:
"Both systems will be built by HPE’s Cray group, and are set to come online in 2023."
mode_13h - Monday, April 12, 2021 - link
N2 gets my vote. With so much compute power in the GPU, they'd probably prefer a larger number of narrower and more efficient cores.SarahKerrigan - Monday, April 12, 2021 - link
I think that's likely, depending on what the timeline for N2 IP availability looks like.name99 - Monday, April 12, 2021 - link
Ah Sarah, you really think "everyone saw this coming"?In the world I live in, last week "everyone" was chattering about how Intel was already back, ready to crush it with Ice Lake Scalable Xeon 3D Turbo Supermax (or whatever the lunatic official name of the product is).
I don't think you can coherently hold in one brain both the idea that "nV is making a serious play for the data center/HPC" AND "Intel will be just fine. Daddy's home and the bad times are over."
I expect than in a week this nV announcement will be forgotten and we'll be back to the fantasy that Intel's all poised to deliver multiple rabbits out of multiple hats over the next few years.
(Don't get me wrong. I'm not saying Intel will never sell another chip. I am saying that we're very close to peak Intel. Will it be 2020 or 2022? No idea. But it won't be 2025, I just don't see that happening. It's gone beyond just process issues now; now we're hitting design issues, product-market fit issues, almost fifty years of accumulated and never paid off technical debt.)
SarahKerrigan - Monday, April 12, 2021 - link
I basically agree. I think we're reaching the point where x86 is going to stop being the unchallenged default for servers, which it has been since the early-mid 2000s. There will be a niche for it indefinitely - folks who need a piece of highly optimized existing software, or people who need a 4+ socket server for running MSSQL, or whatever - but the era where x86 is dominant, rather than one option out of multiple good ones, looks to me like it's probably over, and is extra-super-over for hyperscalers. Amazon already has its own server CPU, Google has announced they will soon, and Microsoft has been speculated to have its own server CPU program too. And beyond that, there's the merchant CPU vendors. This is turning into a bona fide ecosystem, even if it took a few false starts to get there. That doesn't mean it will stick around indefinitely; there's a lot of noise around RV, but right now, ARM is where the high-end IP is. That could change.There's things that could divert this - ARM failing to deliver improvements on the IP side, or AMD starting to execute above the pace they already have been - but I have a hard time imagining a 2025 server market that doesn't have some serious ARM share. Graviton - really Grav2, since Grav was not ever very relevant or really even good - was the beginning, but there will be others.
You can count on it.
eva02langley - Monday, April 12, 2021 - link
The thing is AWS chips are not matching specific x86 chips in the majority of API and even there, the compatibility is a huge issue. And let`s not get into security... I don`t trust Nvidia and their proprietary technology on that aspect.eastcoast_pete - Monday, April 12, 2021 - link
In that regard, and purely on wild speculation, Intel could, in theory (unlikely) pull a massive rabbit out of their hat with Sapphire Rapids, if (!) they a. can deliver it at all, in time, b. Get that on-package HBM design right and c. Then integrate their high-performance Xe GPUs with it. At least theoretically, the parts are there, if they could only execute on them.SarahKerrigan - Tuesday, April 13, 2021 - link
Getting substantial HPC share in GPUs is hard, though, and is as much a software/ecosystem problem as a hardware problem - just ask AMD. Nvidia is the undisputed incumbent in that space, and I think it'll take more than a couple of wins at national labs for Intel or AMD to change that. It's a good start, but time will tell if either of them are able to follow through.silverblue - Tuesday, April 13, 2021 - link
+1 for Top Gun quote.SarahKerrigan - Tuesday, April 13, 2021 - link
It seemed appropriate in context~