64 Cores of Rendering Madness: The AMD Threadripper Pro 3995WX Review
by Dr. Ian Cutress on February 9, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Lenovo
- ThinkStation
- Threadripper Pro
- WRX80
- 3995WX
CPU Tests: Microbenchmarks
A y-Cruncher Sprint
The y-cruncher website has a large amount of benchmark data showing how different CPUs perform when calculating pi up to a given number of digits. Not only are the pi world records present, but below these there are a few CPUs showing the scaling of the hardware, where it shows the time to compute moving from 25 million digits to 50 million, 100 million, 250 million, and all the way up to 10 billion, to showcase how the performance scales with digits (assuming everything is in memory). This range of results, from 25 million to 250 billion, is something I’ve dubbed a ‘sprint’.
I have written some code in order to perform a sprint on every CPU we test. It detects the DRAM, works out the biggest value that can be calculated with that amount of memory, and works up starting from 25 million digits. For the tests that go up to the ~25 billion digits, it only adds an extra 15 minutes to the suite for an 8-core Ryzen CPU. With this test, we can see the effect of increasing memory requirements on the workload and the scaling factor for a workload such as this.
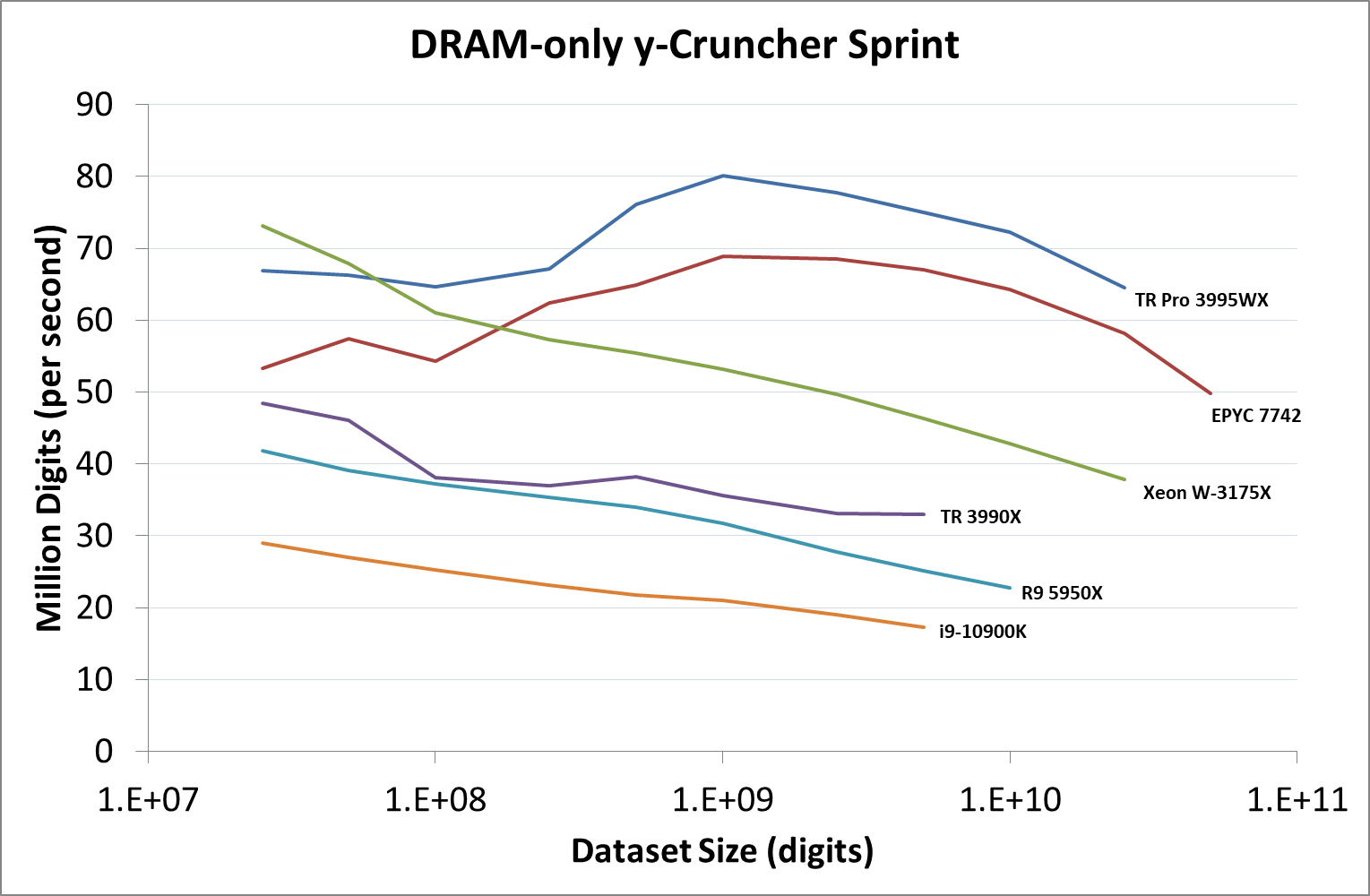
Longer lines indicate more memory installed in the system at the time
For this sprint, we’ve covered each result into how many million digits are calculated per second at each of the dataset sizes. The more cores a system has, the better the compute, and Intel gets an AVX-512 bonus here as well because the software can use AVX-512. But as the dataset gets larger, there is more shuffling of values back and forth between memory and cache, so being able to keep a high bandwidth while also a low latency to all cores is crucial in this test, especially as the test increases.
The 8-channel 64-core TR Pro 3995WX here does very well, peaking at around 80 million per second, and at the end of the test still being very fast. It sits above the EPYC 7742 here due to the fact that it has a higher TDP and frequency. They are both well above the Threadripper 3990X, which only has quad-channel memory, which is the reason for the decrease as the dataset increases.
The W-3175X from Intel has the AVX-512 advantage, which is why the 28 cores can compete with the 64 cores from AMD, however the six-channel memory bandwidth and probably the mesh quickly becomes a bottleneck as each core needs to feed those AVX-512 units. This is the sort of situation where in-package HBM is likely to make a big difference. But at the smaller dataset sizes at least the W-3175X can feed enough data across the mesh to the AVX-512 units for the peak throughput.
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.

Due to a test limitation, we’re only probing the first 64 threads of the system, but the scale out to 128 threads would be identical. This generation of Threadripper Pro is built on Zen 2, similar to Threadripper 3990X and the EPYC 7742, and so we only have quad-core CCXes in play here. A thread speaking to itself has a latency of around 7 nanoseconds, inside a quad-core CCX is around 18-19 nanoseconds, and then accessing any other core varies from 77-89 nanoseconds. Even accessing the CCX on the same chiplet has the same latency, as the communication is designed to ping out to the central IO die first. If Threadripper Pro gets boosted to Zen 3 for the next generation, this will be a big uplift as we’ve already seen with Zen 3. But TR Pro with Zen 3 might only be launched only when Zen 4 comes out, and we’ll be talking about that difference when that happens.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
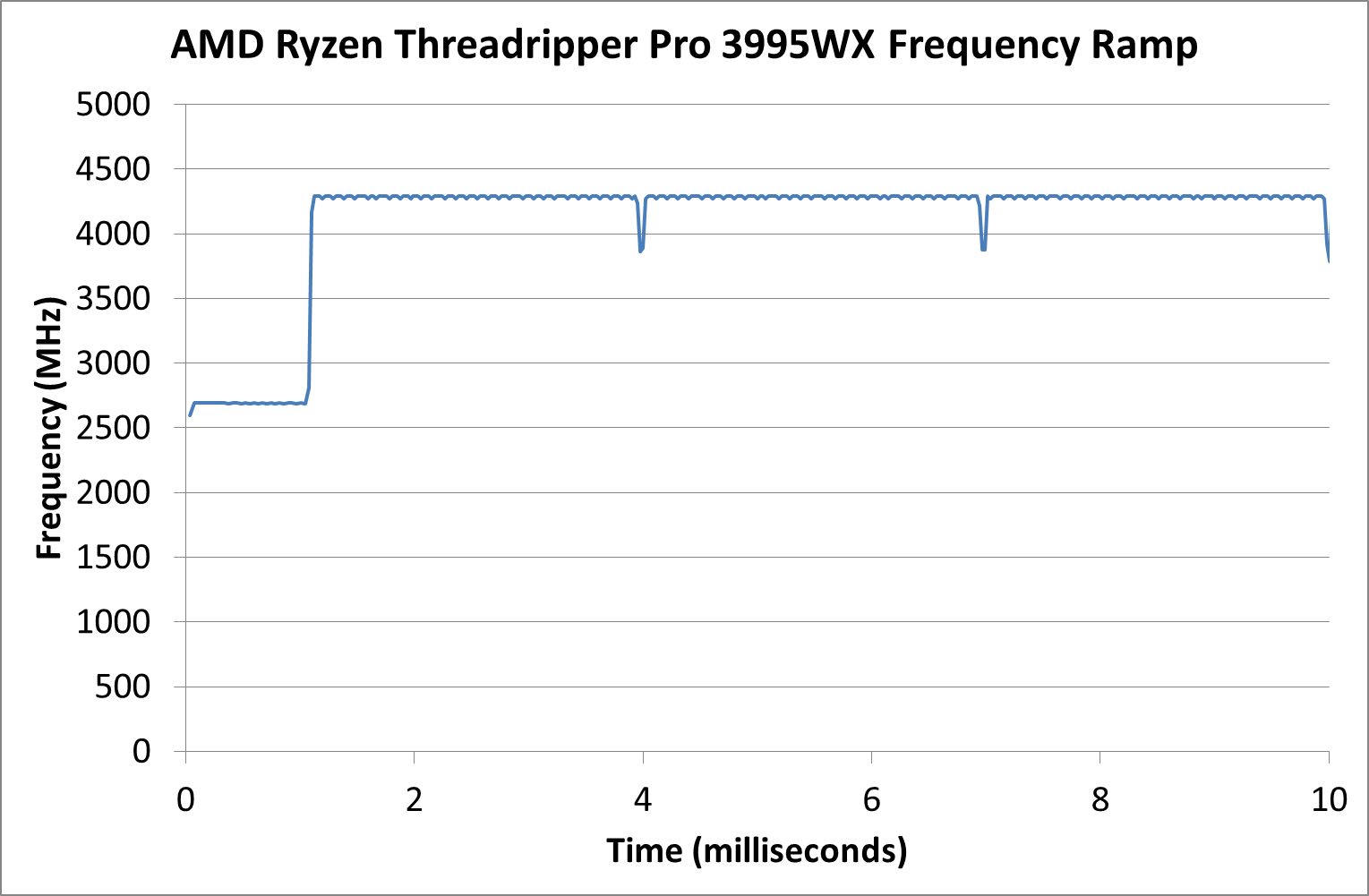
The frequency ramp here is around one millisecond, indicative of AMD implementing its CPPC2 management design.








118 Comments
View All Comments
Oxford Guy - Friday, February 12, 2021 - link
Bulldozer was indeed particularly awful. Abstract names like Xeon are generally less annoying than misapplied real-world names.Qasar - Friday, February 12, 2021 - link
too bad bulldozer and netburst were code names for the architecture, and not marketing names like xeon and threadripper.GeoffreyA - Saturday, February 13, 2021 - link
You're right, but even FX and Phenom were in poorer taste than Athlon, which was sheer gold, I'd say. Is Threadripper good or bad as a name? What I say, or anyone else here says, doesn't matter. Only from a survey can we get a better picture, and even there it's a reflection of popular opinion, a blunt instrument, often misled by the times.Is there a standard of excellence, a mode of naming so tuned to the genius of the language that it never changes? It's evident to everyone that "Interstellar" sounds better than "Invisible Invaders from Outer Space," but we could be wrong and time only can decide the matter. If, in 500 years, people still get a shiver when they hear Interstellar, we'll know that Nolan named his film right.
Back to the topic. I think the spirit of Oxford Guy's comment was: TR and Epyc aren't that good names (which I partly agree with). Whether it inspires confidence in professionals is a different matter. A professional might be an expert in their field but it doesn't mean they're an expert on good names (and I'm not claiming I am one either). It matters little: if the target demographic buys, AMD's bank account smiles. But it's a fair question to ask, apart from sales, is a name good or bad? Which were the best? Does it sound beautiful?Names, in themselves, are pleasurable to many people.
jospoortvliet - Saturday, February 13, 2021 - link
Names should have a few properties if they are to be good.Easy to pronounce (cross-culturally!)
Easy to remember (distinctive)
Not (too) silly/funny
Bonus: have some (clever) relation to the actual product.
Threadripper certainly earns the bonus but might arguably perhaps maybe lose out on the 3rd ‘silly’ point. However, in that regards i would argue it makes a difference how well it fulfills that rather ambitious title, and as we all know the answer is “very well”. Now if threadripper was a mediocre product, not at all living up to its name, I’d judge different but as it stands I would say it is a brilliant name.
GeoffreyA - Saturday, February 13, 2021 - link
Good breakdown that, to test names against. Simplicity, too, wins the day.GeoffreyA - Saturday, February 13, 2021 - link
"Bulldozer was indeed particularly awful"One of the worst. AMD's place names were good in the K8 era, and the painter ones are doing a good job too.
danjw - Saturday, February 13, 2021 - link
You may not be aware of this, but Threadripper, is actually comes from the 80's fashion fad of ripped clothing. ;-)GeoffreyA - Saturday, February 13, 2021 - link
Well, I like it even more then, being a fan of the 80s.Hulk - Tuesday, February 9, 2021 - link
Is the difference in output quality strictly due to rounding/numerical errors when using GPU vs CPU or are there differences in the computational algorithms that calculate the numbers?Kjella - Tuesday, February 9, 2021 - link
Not in terms of color accuracy, not a problem making 10/12 bit non-linear color from 32 bit linear - even 16 bit is probably near perfect. But for physics engines, ray tracing etc. errors can compound a lot - imagine a beam of light hitting a reflective surface where fractions of a degree means the light bounces in a completely different direction. Or you're modelling a long chain of events that cause compounding errors, or the sum of a million small effects or whatever. But it can also just be that the algorithms are a bit "lazy" and expect everything to fit because they got 64 bits to play with. I doubt that much needs ~1.0000000001 precision, much less ~1.0000000000000000001.