The 64 Core Threadripper 3990X CPU Review: In The Midst Of Chaos, AMD Seeks Opportunity
by Dr. Ian Cutress & Gavin Bonshor on February 7, 2020 9:00 AM ESTThe Windows and Multithreading Problem (A Must Read)
Unfortunately, not everything is just as straightforward as installing Windows 10 and going off on a 128 thread adventure. Most home users that have Windows typically have versions of Windows 10 Home or Windows 10 Pro, which are both fairly ubiquitous even among workstation users. The problem that these operating systems have rears its ugly head when we go above 64 threads. Now to be clear, Microsoft never expected home (or even most workstations) systems to go above this amount, and to a certain extent they are correct.
Whenever Windows experiences more than 64 threads in a system, it separates those threads into processor groups. The way this is done is very rudimentary: of the enumerated cores and threads, the first 64 go into the first group, the second 64 go into the next group, and so on. This is most easily observed by going into task manager and trying to set the affinity of a particular program:
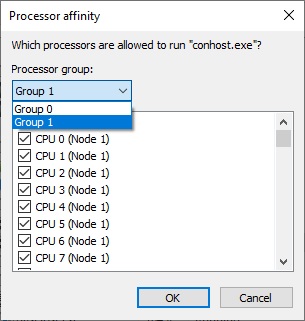

With our 64 core processor, when simultaneous multithreading is enabled, we get a system with 128 threads. This is split into two groups, as shown above.
When the system is in this mode, it becomes very tricky for most software to operate properly. When a program is launched, it will be pushed into one of the processor groups based on load – if one group is busy, the program will be spawned in the other. When the program is running inside the group, unless it is processor group aware, then it can only access other threads in the same group. This means that if a multi-threaded program can use 128 threads, if it isn’t built with processor groups in mind, then it might only spawn with access to 64.
If this sounds somewhat familiar, then you may have heard of NUMA, or non-uniform memory architecture. This occurs when the CPU cores in the system might have different latencies to main memory, such as within a dual socket system: it can be quick to access the memory directly attached to its own core, but it can be a lot slower if a core needs to access memory attached to the other physical CPU. Processor groups is one way around this, to stop threads jumping from CPU to CPU. The only issue here is that despite having 128 threads on the 3990X, it’s all one CPU!
In Windows 10 Pro, this becomes a problem. We can look directly at Task Manager:
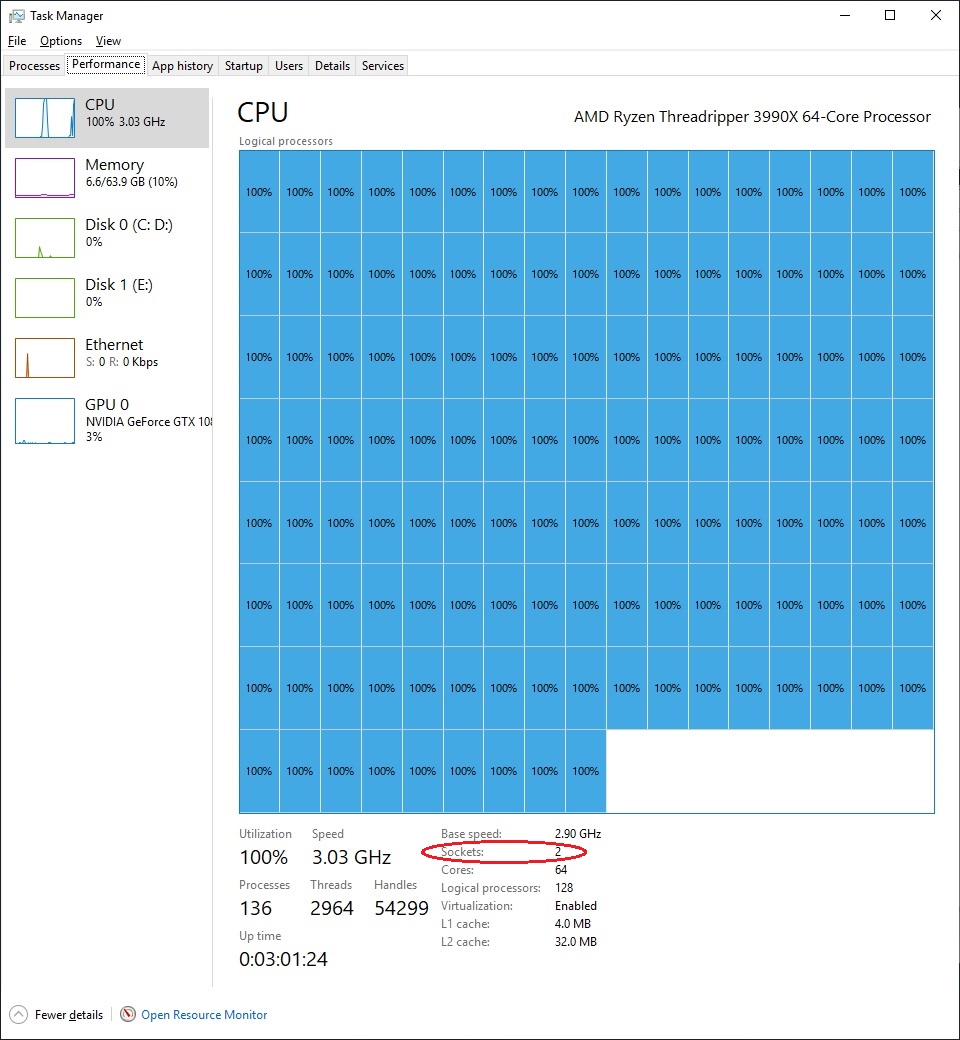
Here we see all 64 cores and 128 threads being loaded up with an artificial load. The important number here though is the socket count. The system thinks that we have two sockets, just because we have a high number of threads in the system. This is a big pain, and the source of a lot of slowdowns in some benchmarks.
(Interestingly enough, Intel’s latest Xeon Phi chips with 72 lightweight cores and 4-way HT for 288 threads show up as five sockets. How’s that for pain!)
Of course, there is a simple solution to avoid all of this – disable simultaneous multithreading. This means we still have 64 cores but now there’s only one processor group.
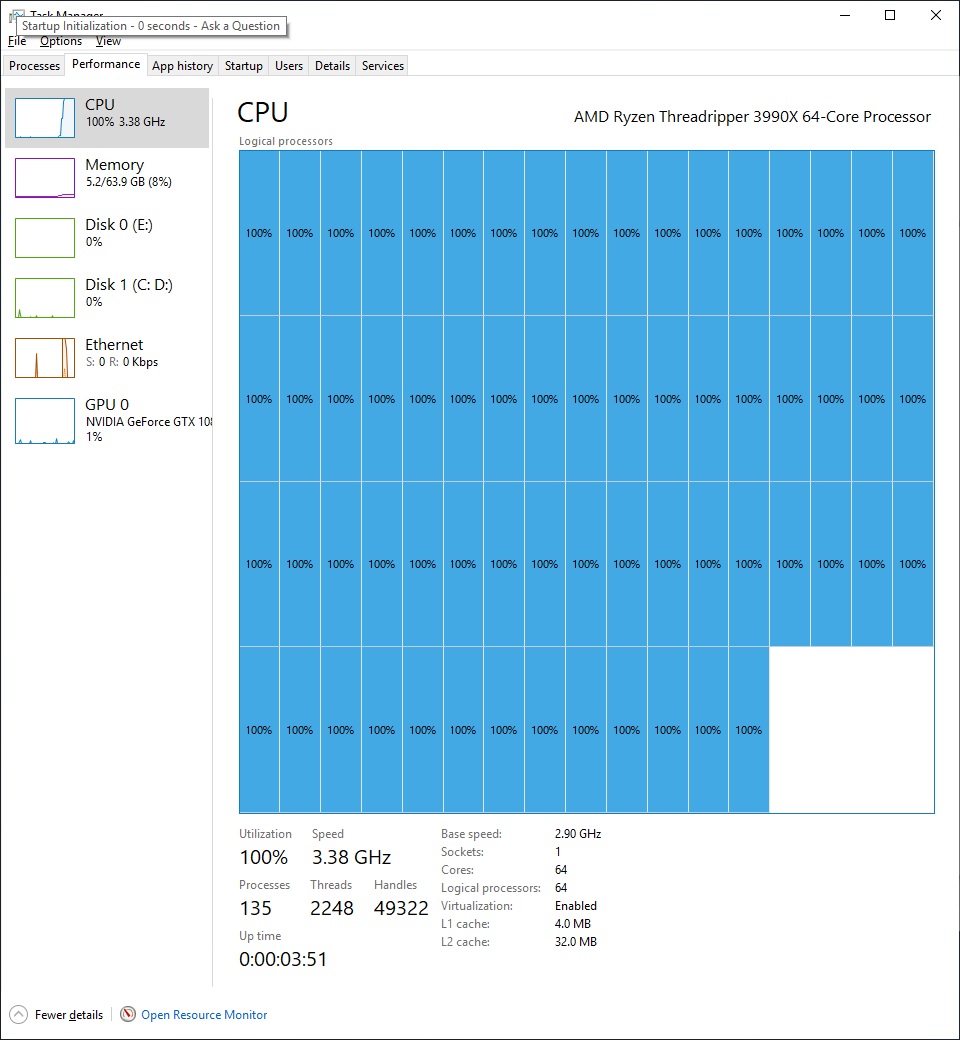
We still have most of the performance on the chip (and we’ll see later in the benchmarks). However, some of the performance has been lost – if I wanted 64 threads, I’d save some money and get the 32-core! There seems to be no easy way around this.
But then we remember that there are different versions of Windows 10.
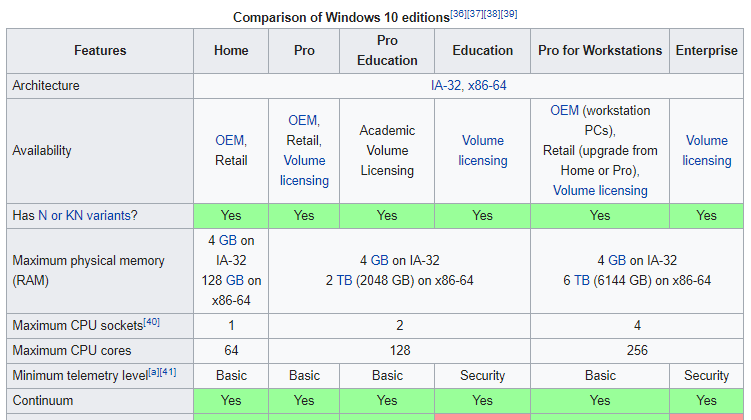
From Wikipedia
Microsoft at retail sells Windows 10 Home, Windows 10 Pro, Windows 10 Pro for Workstations, and we can also find keys for Windows 10 Enterprise for sale. Each of these, aside from the usual feature limitations based on the market, also have limitations on processor counts and sockets. In the diagram above, we can see where it says Windows 10 Home is limited to 64 cores (threads), whereas Pro/Education versions go up to 128, and then Workstation/Enterprise to 256. There’s also Windows Server.
Now the thing is, Workstation and Enterprise are built with multiple processor groups in mind, whereas Pro is not. This has comes through scheduler adjustments, which aren’t immediately apparent without digging deeper into the finer elements of the design. We saw significant differences in performance.
In order to see the differences, we did the following comparisons:
- 3990X with 64 C / 128 T (SMT On), Win10 Pro vs Win10 Ent
- Win 10 Pro with 3990X, SMT On vs SMT Off
This isn’t just a case of the effect SMT has on overall performance – the way the scheduler and the OS works to make cores available and distribute work are big factors.
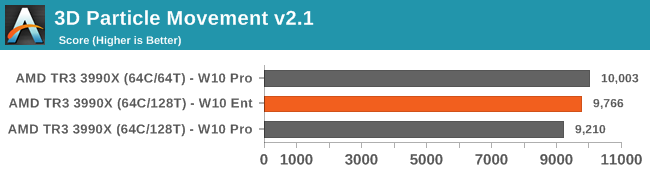
In 3DPM, with standard non-expert code, the difference between SMT on and off is 8.6%, however moving to Enterprise brings half of it back.
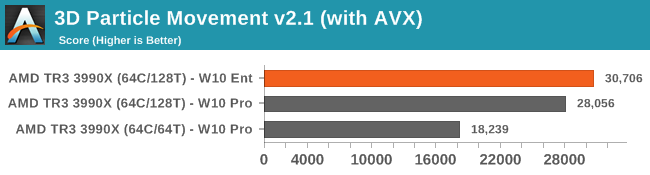
When we move to hand-tuned AVX code, the extra threads can be used and per-thread gets a 2x speed increase. Here the Enterprise version again gets a small lead over the Pro.
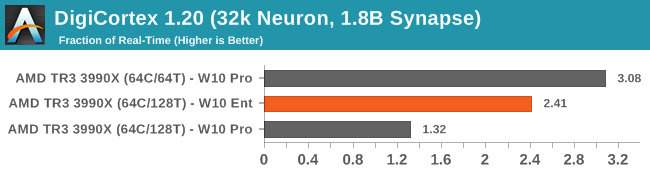
DigiCortex is a more memory bound benchmark, and we see here that disabling SMT scores a massive gain as it frees up CPU-to-memory communication. Enterprise claws back half that gain while keeping SMT enabled.
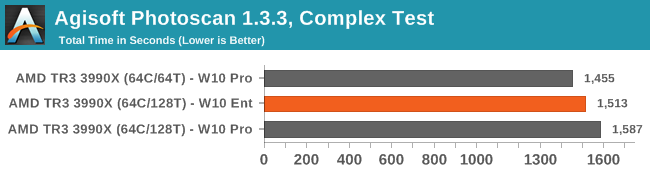
Photoscan is a variable threaded test, but having SMT disabled gives the better performance with each thread having more resources on tap. Again, W10 Enterprise splits the difference between SMT off and on.
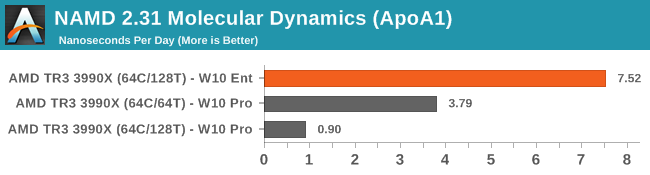
Our biggest difference was in our new NAMD testing. Here the code is AVX2 accelerated, and the difference to watch out for is with SMT On, going from W10 Pro to W10 Ent is a massive 8.3x speed up. In regular Pro, we noticed that when spawning 128 threads, they would only sit on 16 actual cores, or less than, with the other cores not being utilized. In SMT-Off mode, we saw more of the cores being used, but the score still seemed to be around the same as a 3950X. It wasn’t until we moved to W10 Enterprise that all the threads were actually being used.
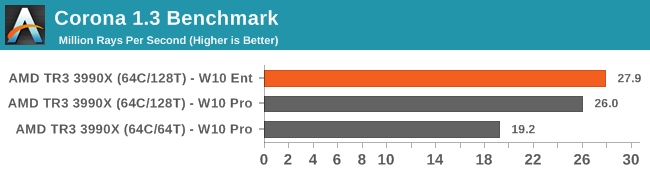
On the opposite end of the scale, Corona can actually take advantage of different processor groups. We see the improvement moving from SMT off to SMT On, and then another small jump moving to Enterprise.
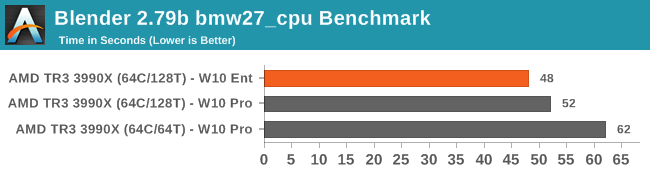
Similarly in our Blender test, having processor groups was no problem, and Enterprise gets a small jump.
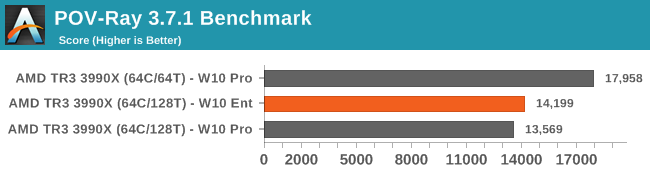
POV-Ray benefits from having SMT disabled, regardless of OS version.
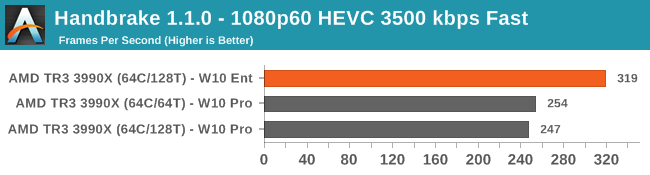
Whereas Handbrake (due to AVX acceleration) gets a big uplift on Windows 10 Enterprise
What’s The Verdict?
From our multithreaded test data, there can only be two conclusions. One is to disable SMT, as it seems to get performance uplifts in most benchmarks, given that most benchmarks don’t understand what processor groups are. However, if you absolutely have to have SMT enabled, then don’t use normal Windows 10 Pro: use Pro for Workstations (or Enterprise) instead. At the end of the day, this is the catch in using hardware that's skirting the line of being enterprise-grade: it also skirts the line with triggering enterprise software licensing. Thankfully, workstation software that is outright licensed per core is still almost non-existent, unlike the server realm.
Ultimately this puts us in a bit of a quandary for our CPU-to-CPU comparisons on the following pages. Normally we run our CPUs on W10 Pro with SMT enabled, but it’s clear from these benchmarks that in every multithreaded scenario, we won’t get the best result. We may have to look at how we test processors >16 cores in the future, and run them on Windows 10 Enterprise. Over the following pages, we’ll include W10 Pro and W10 Enterprise data for completeness.








279 Comments
View All Comments
HStewart - Friday, February 7, 2020 - link
One note on render farms, in the past I created my own render farms and it was better to use multiple machines than cores because of dependency of disk io speed can be distributed. Yes it is a more expensive option but disk io serious more time consuming than processor time.Not content creation workstation is a different case - and more cores would be nice.
MattZN - Friday, February 7, 2020 - link
SSDs and NVMe drives have pretty much removed the write bottleneck for tasks such as rendering or video production. Memory has removed read bottleneck. There are very few of these sorts of workloads that are dependent on I/O any more. rendering, video conversion, bulk compiles.... on modern systems there is very little I/O involved relative to the cpu load.Areas which are still sensitive to I/O bandwidth would include interactive video editing, media distribution farms, and very large databases. Almost nothing else.
-Matt
HStewart - Saturday, February 8, 2020 - link
I think we need to see a benchmark specifically on render frame with single 64 core computer and also with dual 32 core machines in network and quad core machines in network. All machines have same cpu designed, same storage and possibly same memory. Memory is a question able part because of the core load.I have a feeling with correctly designed render farm the single 64 core will likely lose the battle but the of course the render job must be a large one to merit this test.
For video editing and workstation designed single cpu should be fine.
HStewart - Saturday, February 8, 2020 - link
One more thing these render tests need to be using real Render software - not PovRay, Corona and Blender.e
I personal using Lightwave 3D from NewTek, but 3DMax, Maya and Cimema 3d are good choice - Also custom render man software
Reflex - Saturday, February 8, 2020 - link
It wouldn't change the results.HStewart - Sunday, February 9, 2020 - link
Yes it would - this a real 3d render projects - for example one of reason I got in Lightwave is Star Trek movies, also used in older serious called Babylon 5 and Sea quest DSV. But you think about Pixar movies instead scenes in games and such.Reflex - Sunday, February 9, 2020 - link
It would not change the relative rankings of CPU's vs each other by appreciable amounts. Which is what people read a comparative review for.Reflex - Saturday, February 8, 2020 - link
Network latencies and transfer are significantly below PCIe. Below you challenged my points by discussing I/O and storage, but here you go the other direction suggesting a networked cluster could somehow be faster. That is not only unlikely, it would be ahistorical as clusters built for performance have always been a workaround to limited local resources.I used to mess around with Beowulf clusters back in the day, it was never, ever faster than simply having a better local node.
Reflex - Friday, February 7, 2020 - link
You may wish to read the article, which answers your 'honest generic CPU question' nicely. Short version is: It depends on your workload. If you just browse the web with a dozen tabs and play games, no this isn't worth the money. If you do large amounts of video processing and get paid for it, this is probably worth every penny. Basically your mileage may vary.HStewart - Saturday, February 8, 2020 - link
Video processing and rendering likely depends on disk io - also video as far as I know is also signal thready unless the video card allows multiple connections at same time.I just think adding more core is trying to get away from actually tackling the problem. The designed of the computer needs to change.