Arm Announces Neoverse N1 & E1 Platforms & CPUs: Enabling A Huge Jump In Infrastructure Performance
by Andrei Frumusanu on February 20, 2019 9:00 AM ESTN1 Hyperscale Reference Design
A big part of what is defining the N1 Platform as an actual platform, is the fact that Arm is offering a full reference design with a set of IPs that is fully validated by Arm themselves.

Here we see three reference designs, a Neoverse N1 hyperscale design, which we’ll get into more detail shortly, an N1 edge design, and a Neoverse E1 edge design. Arm’s goals with the reference designs is to give vendors “sweet-spot” configuration options that they will then be able to implement with (relatively) minimal effort.
The N1 hyperscale design is what we’ll be covering in more detail as this represents Arm’s most cutting-edge and competitive product.
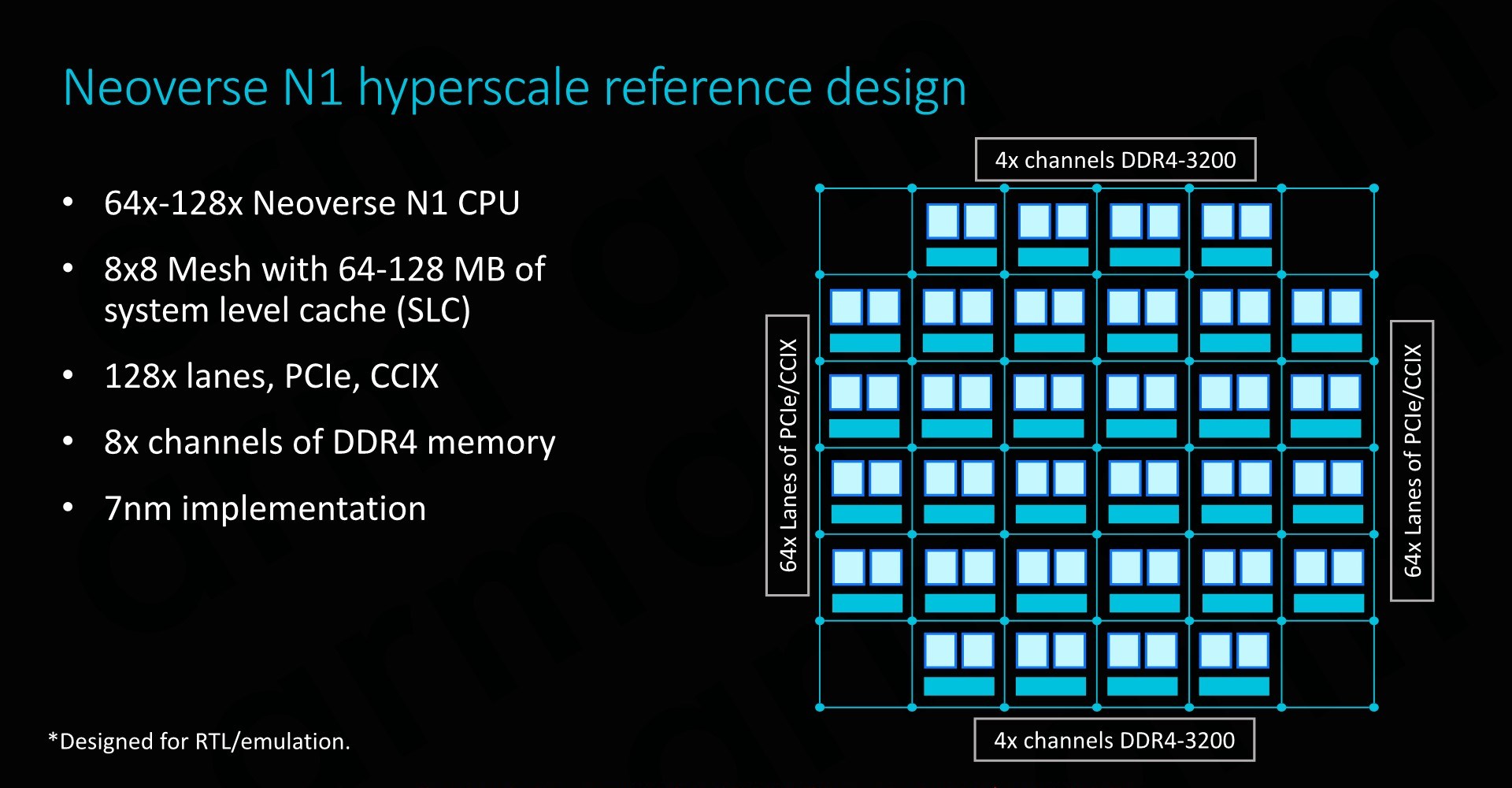
As covered on the previous page, at the heart we find the Neoverse N1 CPU in either 64 or 128 core configurations, integrated in a CMN-600 mesh network with either 64 or 128MB of SLC cache. We also see 128 lanes for PCIe 4 respectively CCIX interfaces which provide plenty of I/O bandwidth.
In terms of memory controllers, Arm employs 8x DD4 interfaces up to 3200MHz. Arm actually has abandoned development of its own memory controllers as customers in most cases opted for their own in-house designs or rather opted to choose IP from other third-party vendors such as Cadence or Synopsys. For the current reference designs Arm’s own DMC-520 was still up-to-date and a well-understood block for the company, although in the future newer memory controllers such as for DDR5 will have to rely on third-party IP. Naturally, the reference design targets the latest 7nm process node.

The physical implementation of the SoC would use replicable hierarchical building blocks for ease of design. A “CPU Tile” consists of the two N1 CPU cores, a slice/bank of the SLC cache as well as part of the CMN’s cross points and home-nodes. This CPU Tile is replicated to generate a “Super Tile”, what is added here is peripheral parts of the SoC such as I/O as well as memory controllers. Finally, replicating the super tile in flipped and mirrored implementations results in the final top-level mesh that is to be implemented on the SoC.

Scaling the design to 128 cores doesn’t represent an issue for the IP, although we’ll be hitting some practical limits in terms of current generation technology. Arm’s 64 core N1 reference design with 64MB of cache on a 7nm process node would result in a die size a little under 400mm², which probably is on the higher end of what vendors would want to target in terms of manufacturability. To alleviate such concerns, Arm also took a page out of AMD’s book and floated the idea of chiplet designs, where each chiplet would communicate over CCIX links. Inherently it’s up to the vendor to decide how they’ll want to design their solution, and Arm provides the essential building blocks and flexibility to enable this.
SmartNIC integration capability is also an important aspect of the design and its flexibility. To maximise compute capacity in large scale system, having accelerated network connectivity is key in actually achieving high throughput in the densest (and efficient) form-factor possible.
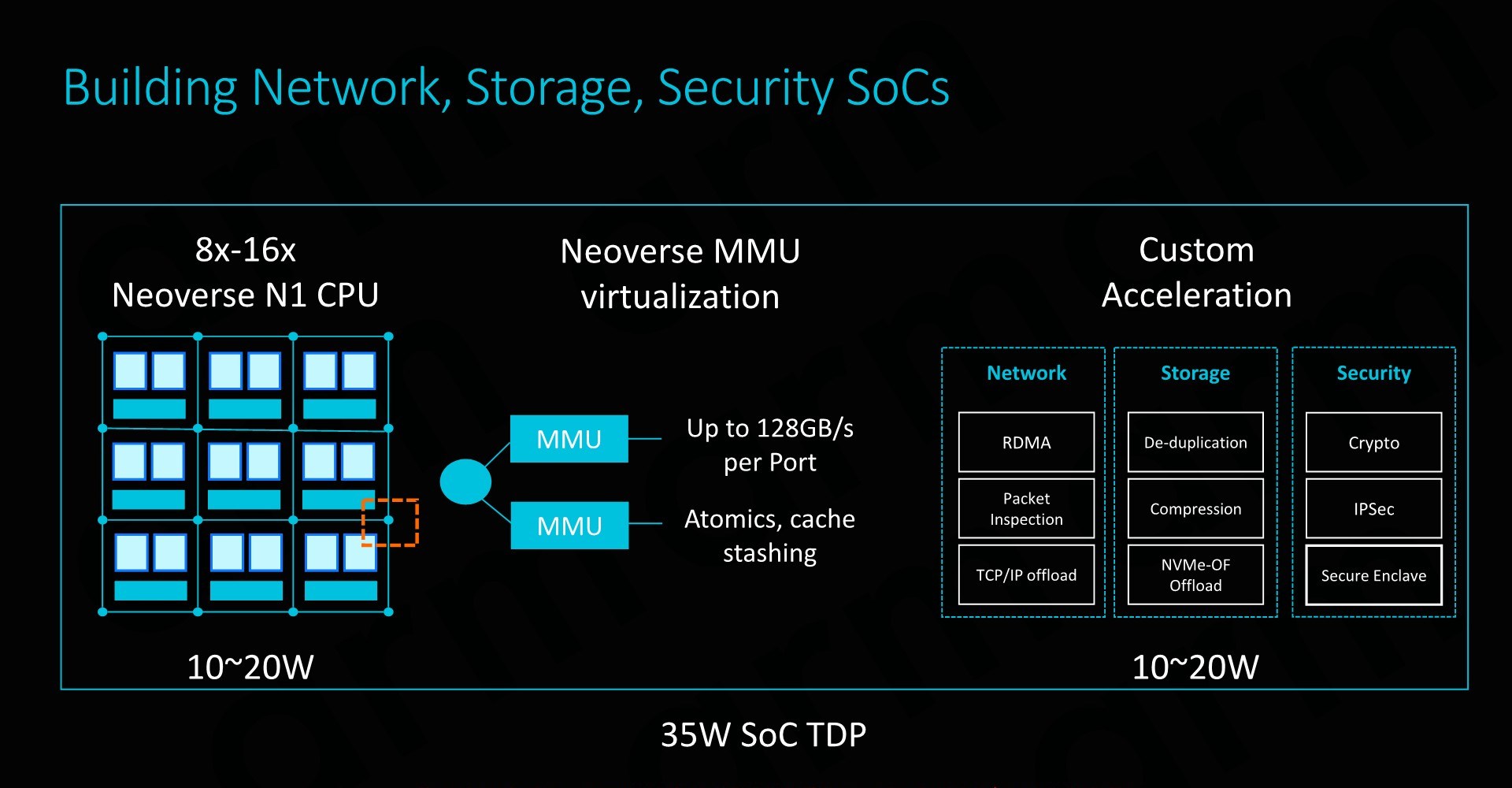
The CMN-600 allows for slave ports on its crosspoints: Here we can see MMUs connected with high bandwidth interfaces of up to 128GB/s. Attaching fixed-function hardware offloading IP thus would be extremely easy to implement.
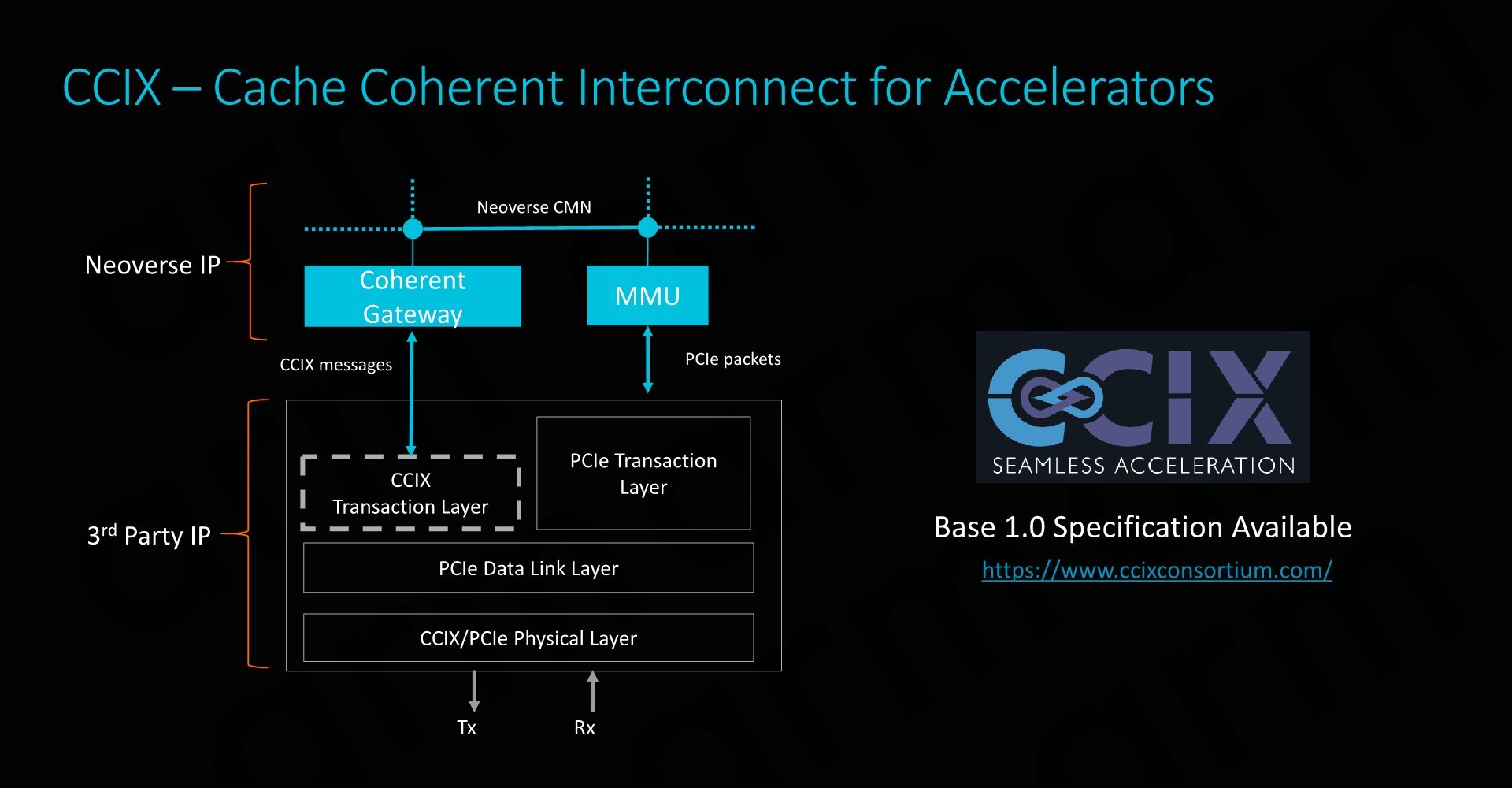
CCIX is extremely important for Arm as it enables its product portfolio to integrate with third-party IP offerings. Enabling cache coherency for external IP blocks is an incredibly attractive feature to have as it massively simplifies software design for the vendors. Essentially what this means is that software simply sees a single huge block of memory, whereas non-coherent systems require drivers and software to be aware and track what part of memory is valid and what isn’t. In terms of IP integration, Arm provides the CCIX coherent gateway that integrates with the CMN-600, while on the other side it’s the onus of the third-party IP provider to provide the CCIX translation layer.
Currently Xilinx will be among the first vendors to offer CCIX-enabled end-products in Q3 2019. With AMD also fully embracing CCIX, there’s some very exciting future potential for third-party accelerator hardware, and we be seeing new use-cases that just weren’t feasible before.
Power/Performance management
While it’s a bit weird to talk about power management in the context of implementation scalability (The average reader might think of it as a thermal/cooling consideration), there’s some very interesting implications in terms of how Arm simplifies the work needed to be done by the vendor.

Along a chip’s logical design, a vendor must also implement a power delivery network that will be able to adequately support the IP. In real-world use-cases this means that the PDN needs to be as robust as to deal with the worst-case power scenario of a component. This is actually quite a headache for many vendors as the design requires complex models and in most cases the PDN will need to be over-engineered in order to offer guarantees of stability, which in turn raises the complexity and cost of the implementation.
Arm seeks to alleviate these concerns by offering extremely fine-grained DVFS mechanisms in the form of a dedicated micro-controller. The controller access detailed activity monitoring units inside the CPU cores, seeing what actual blocks and how many transistors are actually actively switching, and feeding this information back to the system controller to change DVFS states. This provides a certain level of hard-guarantee as to when the CPU enters power-virus-like workloads which can cause current spikes, and avoid them in time. This enables vendors to design their PDNs to more conservative tolerances, saving on implementation cost.








101 Comments
View All Comments
surt - Thursday, February 21, 2019 - link
That raw power comes at a .... power cost. And as soon as you try to start z-stacking your cpus that power is going to be the most important factor.peevee - Tuesday, February 26, 2019 - link
"The future is way more related to modularity than the chip architecture."Debatable. Both ARM and x64 are essentially the same in terms of efficiency if the same levels of performance are required. A breakthrough can only come from in-memory computing, which neither ARM nor x64 can sustain for many reasons.
rahvin - Thursday, February 21, 2019 - link
ARM is not "more efficient at every level". That's just plain fanboi BS. The architecture is the least important aspect of any processor these days.ARM processors were traditionally designed for power efficiency above all else, now that Intel is designing down for efficiency and ARM is designing up for power there will likely be some real competition but so far ARM has not demonstrated that they can provide equivalent power for the same power budget at the high end and Intel has had difficulty matching the lower power budget and performance on the low end (though this is likely due to them wishing to avoid cannibalizing higher end products with performant low power versions).
As ARM tries to enter the server market we'll finally see if they can provide something equivalent, but it's not been a hopeful showing given that all but one ARM server design has been canceled and it's not equivalent to an x86 server processor of the same character in either power or performance.
Wilco1 - Thursday, February 21, 2019 - link
Today you can buy Arm-based servers like Operon A1100, Centriq, ThunderX, ThunderX2, eMAG and HiSilicon. The first Arm supercomputer entered the TOP500 list recently, and Fujitsu has prototypes of their Post-K computer. You can buy Arm compute time from several cloud vendors today, including AWS. That all adds up to one Arm server in your book?rahvin - Thursday, February 21, 2019 - link
ThunderX is gone, displaced by the ThunderX2 which is the Centriq processor after it was abandoned by it's creator. eMAG, A1100 and the HiSilicon Last I saw are all canceled.Commercially you can buy one ARM server, the ThunderX2. Go ahead, TRY to buy one.
Wilco1 - Thursday, February 21, 2019 - link
How could you be so clueless? ThunderX2 is based on Vulcan made by Broadcomm, no relation with Centriq at all. ThunderX is still being used and sold. Centriq is still being sold, a few months ago Gigabyte announced a brand new motherboard for it. eMAG is just announced. HiSilicon/Huawei has 2 generations of Arm servers already and is working on several more. That's the only one that isn't for sale outside of China according to AnandTech.What's next? Are you going to tell us that Arm servers did not beat Xeon and SkyLake in various benchmarks, eventhough the evidence was published in an article on AnandTech?
rahvin - Thursday, February 21, 2019 - link
Your right I confused the Vulcan and the Centriq. The Centriq is dead, the design teams gone,and there is no plan to even spin the silicon from what I've seen. Qualacom abandoned the product under threat from an activist investor. Yea there was a motherboard at CES but that doesn't mean anything at all and there is literally no way to buy one.ThunderX is depreciated (show me where you can buy one, they depreciated the silicon over a year ago, there may still be some inventory out there but I seriously doubt it), ThunderX2 is available, and from everything I saw it's awful. The best work case was as a nginx master server because the compute capacity was so awful. Basically you need a workload with a lot of threads and no actual work to even make it worth anything at all, especially considering the price.
The Huawei junk is a nonstarter, you can't buy it anywhere but China that I've seen and it's not exactly flying off the shelves either. I've seen more ARM servers announced and canceled a year later than any that made it off the shelves into an actual product. So there is an eMag, that's great show me where you can buy it.
That's my point, you can't buy them, other than the ThunderX2 or the Huawei if you want to go to china to get it. The Arm server has been a flash in the pan and I have no doubt it will continue to be so.
FunBunny2 - Wednesday, February 20, 2019 - link
one has to wonder: given the existence of C compilers for any ISA, and thus *nix OS for said ISA, when (or already?) will the maths dictate both the 'optimal' ISA and underlying microarch? both, after all, are just maths optimization problems. to some delta, there is a unique solution.zmatt - Wednesday, February 20, 2019 - link
Baring any major design flaws there shouldn't really be a difference in theoretical performance between ISAs. Its important to note that the ISA isn't the actual logic of the chip, its better thought of as a paper standard a given chip needs to conform to if it wants to be binary compatible. The real determination in performance is the microarchitecture. People conflate this with ISA a lot because they are both architectures but the Micro arch is what describes the actual logic design in the circuit. That is what Intel and AMD apply codenames to. So things like Skylake, Thunderbird, Cortex A53 etc are micro architectures.Wilco1 - Wednesday, February 20, 2019 - link
There certainly are differences between ISAs which cannot be overcome with micro-architecture no matter how much money, power or transistors you throw at it. Given equal resources, the best possible implementations of various ISAs will exhibit major performance differences.