Arm Announces Neoverse N1 & E1 Platforms & CPUs: Enabling A Huge Jump In Infrastructure Performance
by Andrei Frumusanu on February 20, 2019 9:00 AM ESTN1 Hyperscale Reference Design
A big part of what is defining the N1 Platform as an actual platform, is the fact that Arm is offering a full reference design with a set of IPs that is fully validated by Arm themselves.

Here we see three reference designs, a Neoverse N1 hyperscale design, which we’ll get into more detail shortly, an N1 edge design, and a Neoverse E1 edge design. Arm’s goals with the reference designs is to give vendors “sweet-spot” configuration options that they will then be able to implement with (relatively) minimal effort.
The N1 hyperscale design is what we’ll be covering in more detail as this represents Arm’s most cutting-edge and competitive product.
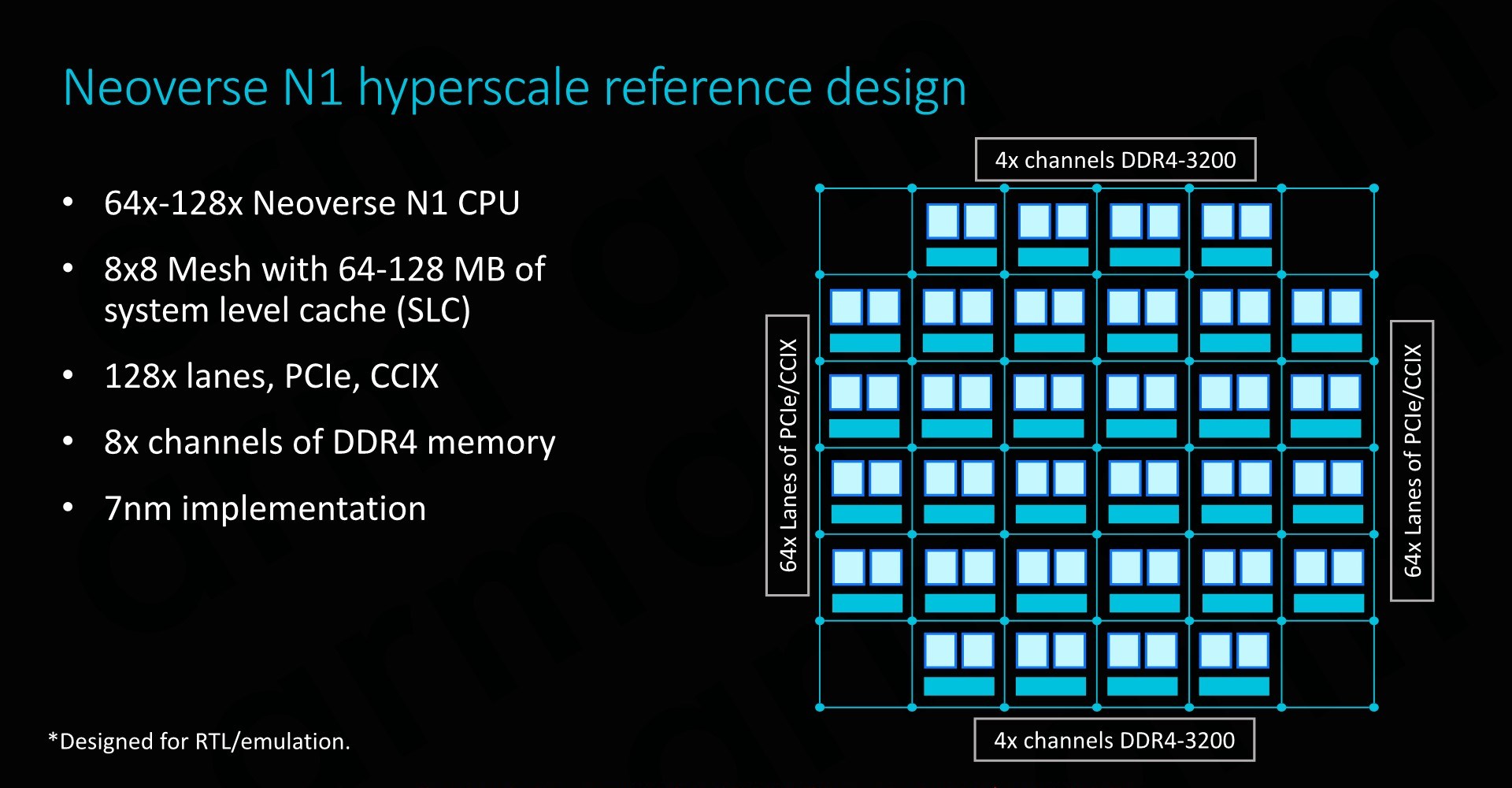
As covered on the previous page, at the heart we find the Neoverse N1 CPU in either 64 or 128 core configurations, integrated in a CMN-600 mesh network with either 64 or 128MB of SLC cache. We also see 128 lanes for PCIe 4 respectively CCIX interfaces which provide plenty of I/O bandwidth.
In terms of memory controllers, Arm employs 8x DD4 interfaces up to 3200MHz. Arm actually has abandoned development of its own memory controllers as customers in most cases opted for their own in-house designs or rather opted to choose IP from other third-party vendors such as Cadence or Synopsys. For the current reference designs Arm’s own DMC-520 was still up-to-date and a well-understood block for the company, although in the future newer memory controllers such as for DDR5 will have to rely on third-party IP. Naturally, the reference design targets the latest 7nm process node.

The physical implementation of the SoC would use replicable hierarchical building blocks for ease of design. A “CPU Tile” consists of the two N1 CPU cores, a slice/bank of the SLC cache as well as part of the CMN’s cross points and home-nodes. This CPU Tile is replicated to generate a “Super Tile”, what is added here is peripheral parts of the SoC such as I/O as well as memory controllers. Finally, replicating the super tile in flipped and mirrored implementations results in the final top-level mesh that is to be implemented on the SoC.

Scaling the design to 128 cores doesn’t represent an issue for the IP, although we’ll be hitting some practical limits in terms of current generation technology. Arm’s 64 core N1 reference design with 64MB of cache on a 7nm process node would result in a die size a little under 400mm², which probably is on the higher end of what vendors would want to target in terms of manufacturability. To alleviate such concerns, Arm also took a page out of AMD’s book and floated the idea of chiplet designs, where each chiplet would communicate over CCIX links. Inherently it’s up to the vendor to decide how they’ll want to design their solution, and Arm provides the essential building blocks and flexibility to enable this.
SmartNIC integration capability is also an important aspect of the design and its flexibility. To maximise compute capacity in large scale system, having accelerated network connectivity is key in actually achieving high throughput in the densest (and efficient) form-factor possible.
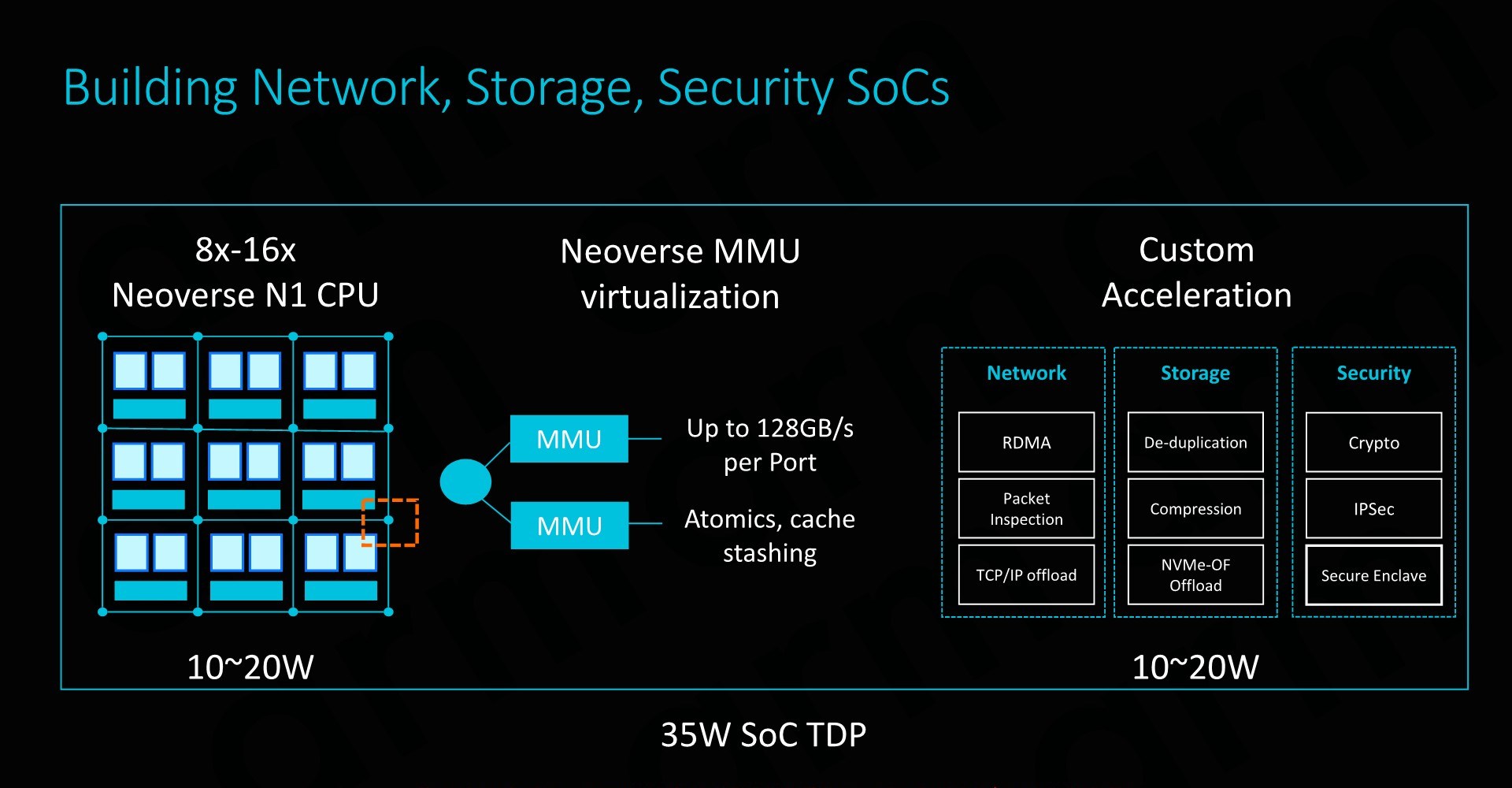
The CMN-600 allows for slave ports on its crosspoints: Here we can see MMUs connected with high bandwidth interfaces of up to 128GB/s. Attaching fixed-function hardware offloading IP thus would be extremely easy to implement.
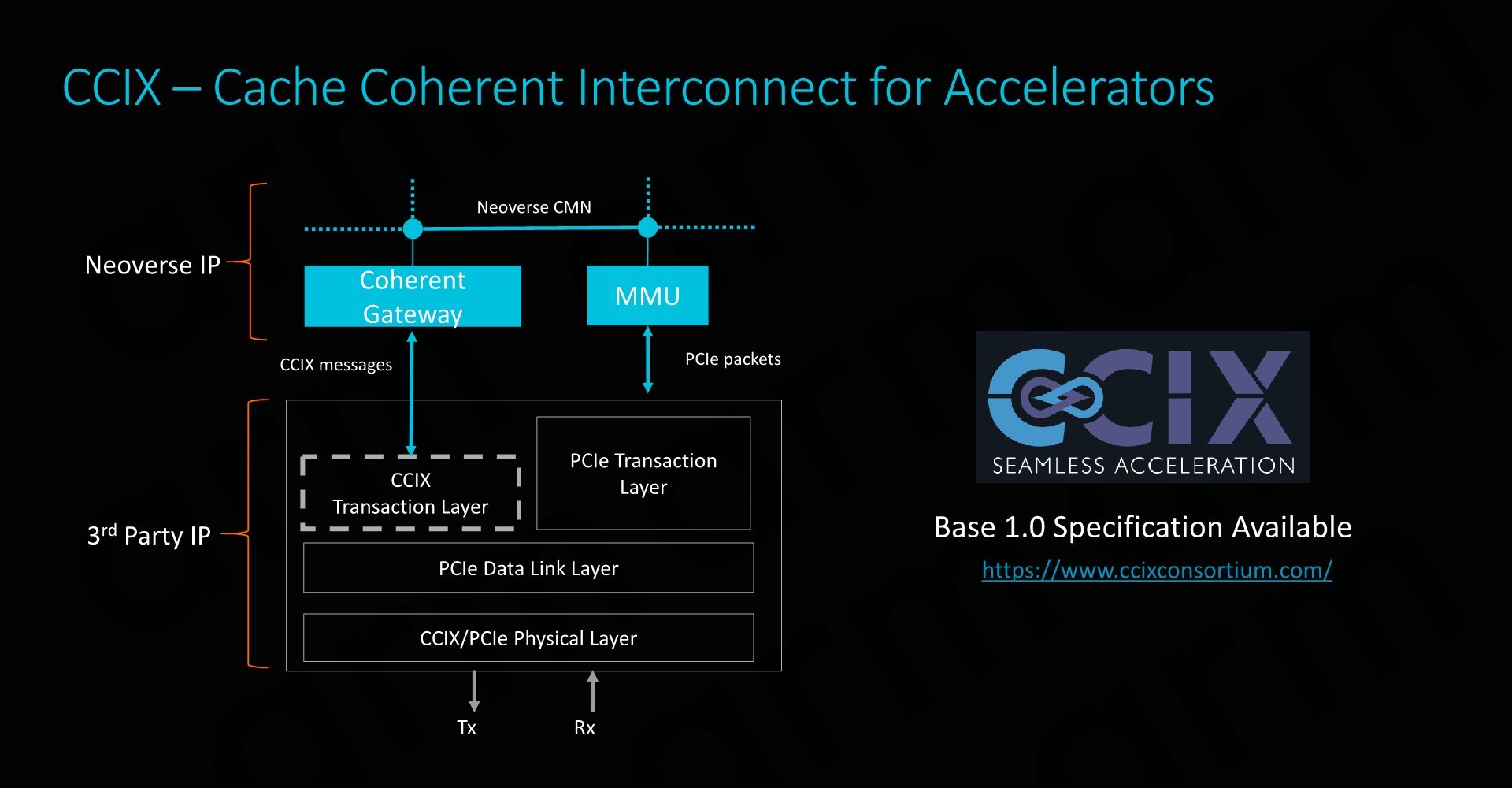
CCIX is extremely important for Arm as it enables its product portfolio to integrate with third-party IP offerings. Enabling cache coherency for external IP blocks is an incredibly attractive feature to have as it massively simplifies software design for the vendors. Essentially what this means is that software simply sees a single huge block of memory, whereas non-coherent systems require drivers and software to be aware and track what part of memory is valid and what isn’t. In terms of IP integration, Arm provides the CCIX coherent gateway that integrates with the CMN-600, while on the other side it’s the onus of the third-party IP provider to provide the CCIX translation layer.
Currently Xilinx will be among the first vendors to offer CCIX-enabled end-products in Q3 2019. With AMD also fully embracing CCIX, there’s some very exciting future potential for third-party accelerator hardware, and we be seeing new use-cases that just weren’t feasible before.
Power/Performance management
While it’s a bit weird to talk about power management in the context of implementation scalability (The average reader might think of it as a thermal/cooling consideration), there’s some very interesting implications in terms of how Arm simplifies the work needed to be done by the vendor.

Along a chip’s logical design, a vendor must also implement a power delivery network that will be able to adequately support the IP. In real-world use-cases this means that the PDN needs to be as robust as to deal with the worst-case power scenario of a component. This is actually quite a headache for many vendors as the design requires complex models and in most cases the PDN will need to be over-engineered in order to offer guarantees of stability, which in turn raises the complexity and cost of the implementation.
Arm seeks to alleviate these concerns by offering extremely fine-grained DVFS mechanisms in the form of a dedicated micro-controller. The controller access detailed activity monitoring units inside the CPU cores, seeing what actual blocks and how many transistors are actually actively switching, and feeding this information back to the system controller to change DVFS states. This provides a certain level of hard-guarantee as to when the CPU enters power-virus-like workloads which can cause current spikes, and avoid them in time. This enables vendors to design their PDNs to more conservative tolerances, saving on implementation cost.








101 Comments
View All Comments
WinterCharm - Wednesday, February 20, 2019 - link
There's a gigantic Arm vs x86/64 battle brewing for the entire computer industry. ARM is just more efficient at every level, and if software is properly optimized it performs brilliantly.eva02langley - Wednesday, February 20, 2019 - link
However, it doesn't have the raw power required for many fields like scientific, compute and research. The core-count is also a huge factor in the upcoming future and unless you develop a chiplet approach, ARM is going to face the same issue of monolithic chips.The next chiplet evolution will require stacking. The future is way more related to modularity than the chip architecture. Don't get me wrong, the more advancement, the better for everyone, but I don't believe ARM is going to render x86 obsolete, hovwever I believe multi-chips SoC are going to render monolithic chip obsolete in the computer world.
SarahKerrigan - Wednesday, February 20, 2019 - link
Sure it does. There are ARM supercomputers, and this very article shows an N1 core outperforming Zen on single-thread, and both Zen and SKL-SP on throughput.HStewart - Wednesday, February 20, 2019 - link
I think you are forgetting the very nature of RISC (Arm) vs CISC (x86) architectures. By the nature of designed of RISC - reduce instruction set, it takes more instruction to execute same operation than CISC. For simple stuff RISC can likely do better but remember also modern x86 based CPU also break down more complex instructions in simpler instruction so it can run one multiple pipelines.SarahKerrigan - Wednesday, February 20, 2019 - link
Dude, I work in the semi industry, and I've designed pipelined cores. Saying "ARM's workload-demonstrated higher performance doesn't matter because x86 is CISC" is idiotic.SPEC isn't "simple stuff." It is a selection of extremely compute-intensive workstation loads, one that the whole industry - including Intel - uses to demonstrate comparative performance.
HStewart - Wednesday, February 20, 2019 - link
The biggest thing I found that seems misinformation is statement that these are estimates and this chip is simulated which tells me they don't need the real numbers.All I am saying is that CISC instructions can do more than RISC instructions per instruction, and it depends on compiler to take advantage of the those instructions. Please note I never sated it does not matter and that was in your words. I just mention considerations need to take in account of different architextures and the fact they are comparing future simulated designed to last year designs.
Andrei Frumusanu - Wednesday, February 20, 2019 - link
> All I am saying is that CISC instructions can do more than RISC instructions per instructionNobody cares. If the performance per clock is same or higher, you're just arguing about semantics.
Internally CISC processors break things down into RISC like µOps anyway.
ZolaIII - Wednesday, February 20, 2019 - link
@Andrei Frumusanu what would be estimated size of an A55 core with similar amount of cache as on represented E1 on 7nm lithography? I am very curious about that one. Also comparation to the A72 & A73 should be a good thing as ARM clames it reaches their level of performance. Its very interesting first born (SMT) and much needed one.zmatt - Wednesday, February 20, 2019 - link
When people talk about complex instructions they don't mean something like find the derivative of x^2. They mean something like a conditional move operation. The speed advantages on paper between RISC and CISC are in theory a wash. This is because while CISC can conceivably do more in an instruction, RISC can do more instructions per clock generally. In the real world the simplicity of RISC means usually, all other things being equal, the chips are simpler and can run higher clocks, draw less power and generate less heat for a given level of performance.x86 chips haven't actually been CISC since the mid 90's. Both Intel and AMD have been making chips that take the CISC instructions and run them through an instruction decoder that then hands RISC instructions to the actual cpu. Yes this does incur some overhead but it frees up cpu design quite a bit without being so closely tied to backwards compatibility.
The fact that modern x86 chips ultimately are actually executing code as reduced instruction sets shows you don't understand the concept.
Wilco1 - Wednesday, February 20, 2019 - link
x86 is still a CISC ISA irrespectively of how it executes instructions. Note that compilers predominantly use the simpler instructions, rather than the microcoded instructions and that's why it's possible for x86 to be fast at all.